

Crawl Outage - An Update and What We're Doing
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
** Latest update: Monday, October 10, 2011 11:30am PDT: Historical crawl data has now been completely restored! Please email [email protected] if you have any issues. Thanks :)
**Update Friday, September 30, 2011 10:36am PDT: CRAWL SERVICE IS LIVE! We have turned on crawl service in the PRO app and the Test Crawl tool. Campaigns will have the most recent crawl data, however, historical data will be spotty as it filters in over the next week. THANK YOU ALL SO MUCH FOR YOUR PATIENCE! The SEOmoz community is truly amazing!
**Update Friday, September 30, 2011 8:10am PDT: We are activating the front end of the crawl service today after working through a small hiccup last night due to the missing historical data in campaigns. This was resolved last night and we should be able to turn crawl service back on today. The back end crawl service has been working properly the past few days so campaigns will see their most recent data, however, historical data will be spotty and will filter in over the next week.
**Updated: Tuesday, September 27, 2011 9:30am PDT
**Updated: Monday, September 26, 2011 11:30am PDT
Howdy folks! I wish I was writing you with better news, but in the spirit of TAGFEE, we want you to be as informed as possible about your PRO membership:
Due to a major PRO web crawler service outage that occurred on Friday evening, crawler-related PRO features (link analysis and crawl diagnostics) are currently disabled. However, rankings, on-page optimization, and all tools except Crawl Test are functional.
It's our best estimate that we will have all service functionality restored by Thursday, Sept. 29., however full historical crawl data will not be available until Monday, Oct. 10. We will be doing our very best to beat these estimates.
So what the *bleep* happened!?
Amazon turned the lights out on us. Well, not exactly—I’ll explain. We host a number of our web applications from Amazon Web Services (AWS). For many of these hosts we pay a fixed rate per hour, however AWS offers an alternative billing model called spot instance pricing. Spot instance pricing is a method for purchasing excess computing power from AWS at a respectable discount. Everybody wins, we get a great price for the hundreds of computers we use daily while AWS is able to sell a resource that’s otherwise just sitting around idle.
But the use of spot instance pricing comes at a risk: the computers hosting your services are only allocated to you as long as there is still excess capacity and that no one else is willing to bid more for those hosts than you are. If someone comes along offering to pay more, then AWS may revoke your hosts without any warning, leaving you to rebuild your services from scratch. This is not so bad if you can ensure you have enough computers left to still service requests… and therein lays the problem.
Our Mistake
The contract of spot instance pricing is quite clear: your servers may be arbitrarily taken from you, so you must be strategic about its usage. We unfortunately did not apply good strategy to our PRO web crawler configuration. Almost all of our service hosts were spot instances allocated with a dangerously low bid price (e.g. $2.00/hour), and they were all clustered within the same AWS availability zone (more on this later).
So we put ourselves at risk with a low bid price, excessive use of spot instance pricing, and a poor distribution of hosts across AWS availability zones. We bet that there’d be little to no chance that AWS would reclaim our spot instance hosts but we bet very wrong. At approximately 6 PM PST, AWS terminated approximately 50% of our active spot instance hosts in the PRO crawler service cluster. Around this same time, the going spot instance price shot up to $2, our maximum bid price, which triggered this culling of our service hosts.
Losing half our hosts wasn’t entirely catastrophic, however bad. In fact, it was a salvageable situation but then it got much worse. At 9PM PST we lost all of our service hosts that were spot instances (> 90%). The going spot instance price had jumped to $2.51/hour at this time, and given most of our hosts were bid at the price of $2/hour we effectively forfeited all rights to our previous claims. Our service wasn’t broken; it was just plain gone!
This pretty graph from AWS accurately documents the spot instance pricing timeline for the day in question:
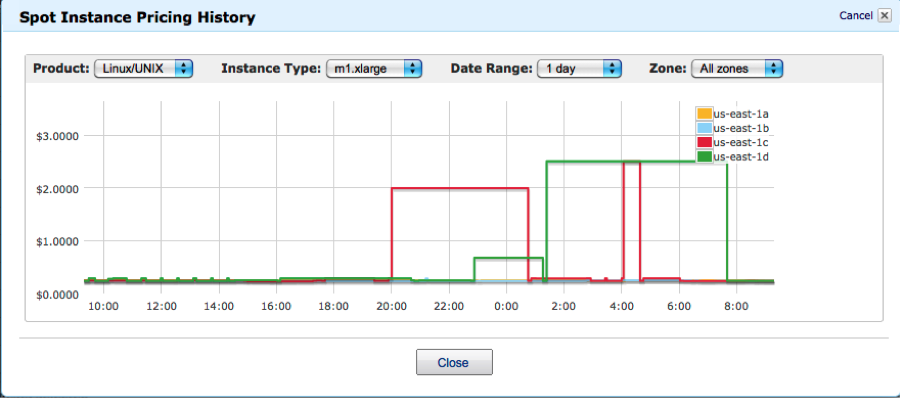
Three practices that could have prevented this from occurring:
1) Use a spot instance price that is commensurate with the value of the service.
If a host was very critical to service functionality, we should’ve bet a much higher price than the $2/hour. Using the spot instance pricing chart as a guide we should have at least used a bid of $3/hour or more to ensure better chance of avoiding host reclamation by AWS.
Could we have predicted this optimal bid price? Likely not. Regardless, we should’ve bid what we thought the continued functioning of our service was worth. I think it’s easy to appreciate we now find that value much higher than the $2/hour we’d originally bid.
2) Distribute hosts across multiple availability zones.
The initial increase in spot instance price occurred in one availability zone (us-east-1c), with the secondary increases in us-east-1c and us-east-1d. Had we spread our bets across multiple availability zones, we could have weathered this price volatility with at least half of our service hosts intact, even at the bid price of $2/hour.
Although we were aware that prices could vary by availability zone, we did not use this to hedge our bets more effectively.
3) Use a mix of on-demand and spot instance pricing.
On-demand priced hosts use a different pricing strategy where you agree to pay a fixed amount per hour to AWS but in return you get certain guarantees about your host claim, most notably it won’t be arbitrarily taken from you due to demand. Had we diversified our portfolio between on-demand and spot instance pricing we could’ve ensured at least minimal functionality of our service in the worst case while enjoying some good amount of cost savings in the best case.
As with any critical investment you have to be strategic about minimizing your downside; we will do this moving forward.
So where are things?
To be frank, we are absolutely mortified that we’ve had to disable such an indispensable product feature as crawl diagnostics, especially when this service outage was otherwise avoidable. We are literally working day and night to re-enable the PRO app crawler service. Currently, we are rebuilding the API servers, the underlying NoSQL data store (Cassandra), and the various processing and crawling hosts. We are being very careful as we do this to avoid the previous mistakes, being strategic about diversifying pricing type (on-demand vs. spot-instance), distributing across availability zones and using a very competitive spot-instance bidding price.
Most of the aforementioned service components are pretty easy to restore, but we have one unfortunate problem that will somewhat delay full restoration of the service: the terabytes of data generated by the hundreds of thousands of crawls we’ve executed over the last nine months. We must load this data from our backups (securely stored in AWS S3) into our NoSQL data store, something that by no means can be done quickly.
Being perfectly transparent, this is an operation that could take the full duration of a week. We certainly don’t want to make anyone wait a full week just to see data that’s already a week out of date, so we plan to be a bit more clever with this service restoration, choosing the most optimal path to populate our database while also ensuring we preserve our weekly crawl cycle. Do we have all the solutions in place to achieve these goals? Not immediately, but we are making great progress and I’m very confident we will have more optimistic projections about service restoration in the next several days.
Ok, so how exactly does this affect me again?
As a PRO member you can still:
- Create new campaigns
- Check your rankings
- Manage keywords
- Check your on-page SEO
- Run reports
- Check your backlinks & traffic data
- Use Open Site Explorer
- Watch webinars
- Ask & answer questions in PRO Q&A
For the next week you won't be able to access:
- Crawl diagnostics for any of your campaigns
- PRO Dashboard will show 0 pages crawled
- SEO Web Crawler in Research Tools
Also as a reminder, none of the data is lost, we just need time to rebuild so we can access it.
In the meantime, rest assured that we are doing everything we can to get your PRO functionality back up and running like it’s meant to be. We realize that many of you rely on this data to optimize your company’s and clients’ sites, and want to return service ASAP so you can continue to do what you do so well. Thank you for hanging in there with us as we learn from our mistakes.
I'm sure you're all wondering about your data - here are few answers to those burning questions:
- What happened to my data? No worries - your data has not been lost and is safe. You'll be able to see your full historical data by October 10.
- What has been affected, exactly? When can I use those features again? Crawl Diagnostics is currently unavailable. You'll be able to access the feature and new data by September 29 (but historical data will be unavailable until October 10).



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.