

New Edition of the Ranking Factors for 2011 is Now Live!
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
Since 2005, SEOmoz has released a new version of the Search Ranking Factors survey every two years, a piece of content that many in the SEO world have used and referenced. This year, we've continued that tradition and added a whole new element of research, comparing the aggregated opinions of 132 SEOs around the world with correlation data from over 10,000 results in Google.
Because this document is quite large, we've divided it into a number of sub-sections based on the type and focus of the data. This intro video can help provide some more information (and is available on the overview page as well).
Included in the ranking factors, you'll find the traditional list of factors broken down into sections such as domain level keyword usage features (which describe things like exact match domains, using the keyword in the root or subdomain name, etc) or page level link metrics (which refer to items like quantity of links to the page, mozRank, etc). These opinion data points are, however, in a new format that we hope helps make them a bit more digestable. Here's the page-level traffic metrics section:
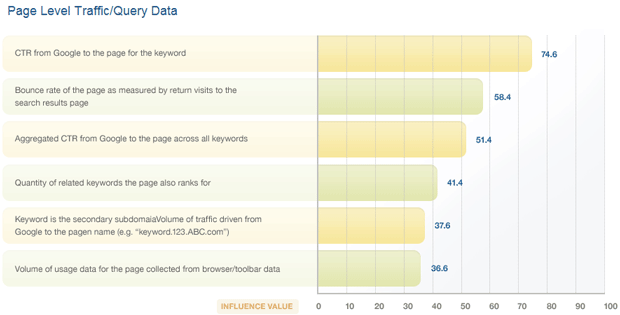
Rather than showing the old 0-5 importance scale along with the "degree of consensus" calculated on standard deviation, we're trying this new format, which highlights relative importance of metrics in a single section based on the aggregation of the voters' ordering. Those elements that are very high on the "influence value" tended to be consistently rated as more important that features below them. The degree of difference between influence values shows, on the 100-point scale, how much the average of the votes differed. In this manner, we hope to illustrate the average of voters' opinions in a simple, visual chart.
Alongside (well, actually usually vertically above) these opinion data points are the results of our correlation research on 10,271 results. You can read lots of detail about the methodology here (vetted by our in-house data scientist, Dr. Matt Peters), but the basic idea is to show features that predict higher or lower rankings for pages in the search results. I've tried to visually illustrate this with my homemade crappy graphics below:
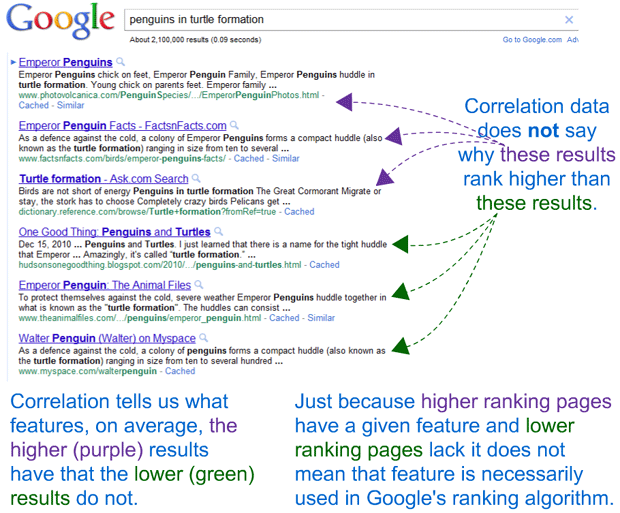
Just as with the social correlation data we released in mid-April (which comes from this same research), please be careful not to confuse correlation and causation. There are plenty of features that are correlated positively or negatively with rankings in Google that are almost certainly not actual parts of Google's ranking algorithm. For example, here's a couple page-level, keyword agnostic features that have reasonably positive correlations with higher rankings in the results:
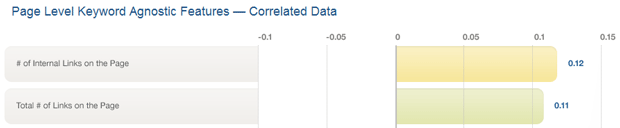
I doubt any SEO truly believes that the number of internal links on a page (not pointing to the page, just in the page HTML code) is an element of Google's ranking algorithm, or that by adding more internal links to a page, one could rise in the rankings. However, the positive correlation does exist. Perhaps large, powerful, important sites simply tend to have lots of internal-pointing links on their pages, and since these rank well, the correlation is an artifact of that overlap? Or maybe it's something else entirely that we haven't thought of yet. This is a good way to think of correlation - as an interesting feature that higher/lower ranking pages have that the curious should explore to discover why it might exist.
The ranking factors also contain some very cool charts based on answers that our panel of 132 experts provided to specific questions. You can find these in the predictions + opinions section of the report.
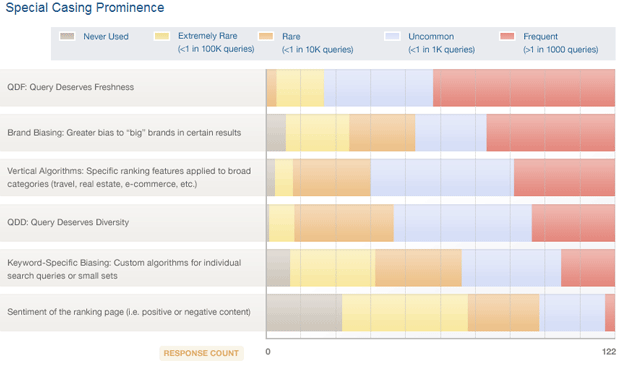
As an example, in the question above, we asked our voters which "special casing" elements of Google's algorithm they saw most frequently influencing the search results. You can see that QDF (Query Deserves Freshness) was thought to be the most prominent of these, while voters felt sentiment analysis of content was rarely in use.
For those interested, I've compiled some of the findings that we at SEOmoz find most interesting, useful, valuable or just plain weird :-) below in a slide deck I presented at SMX Elite in Sydney, Australia. If you're looking for the high level takeaways, this presentation may be useful (and it contains lots of good caveats about the data, too).
Ranking Factors Data 2011: SMX Elite Sydney View more presentations from Rand Fishkin
The 2011 Ranking Factors offers a wealth of depth and detail, and I'm extremely excited to share it with everyone in the marketing community. As always, we're making the full raw data and methodology available and we invite peer review and critiques. Matt and I will both try to be in the comments regularly over the next few days to help answer questions, and if you've got a strong math background and want to tackle any particular details, you can also drop Matt a direct line (Matt(at)SEOmoz(dot)org).
Enjoy the data and please help me in giving huge thanks to our 132 voters, who put in tireless hours going through the survey process.
p.s. For those interested in comparisons, the old 2009 ranking factors is now here (though, methodology and presentation of data is quite different, so a 1:1 may not be entirely fair).
p.p.s. Linkscape's index also updated today with fresh linky goodness in Open Site Explorer, the Web App and the mozBar. I'll have more on that in a post tomorrow or Wednesday.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.