

Rewriting the Beginner's Guide Part IV Continued - Canonical and Duplicate Versions of Content
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
I'm currently working on re-authoring and re-building the Beginner's Guide to Search Engine Optimization, section by section. You can read more about this project here.
Canonical & Duplicate Versions of Content
Why Canonical Versions of Content are Critical to SEO
Canonicalization can be a challenging concept to understand (and hard to pronounce - "ca-non-ick-cull-eye-zay-shun"), but it's essential to creating an optimized website. The fundamental problems stem from multiple uses for a single piece of writing - a paragraph or, more often, an entire page of content will appear in multiple locations on a website, or even on multiple websites. For search engines, this presents a conundrum - which version of this content should they show to searchers? In SEO circles, this issue often referred to as duplicate content - described in greater detail here.
The engines are picky about duplicate versions of a single piece of material. To provide the best searcher experience, they will rarely show multiple, duplicate pieces of content and thus, are forced to choose which version is most likely to be the original (or best).

Canonicalization is the practice of organizing your content in such a way that every unique piece has one and only one URL. By following this process, you can ensure that the search engines will find a singular version of your content and assign it the highest achievable rankings based on your domain strength, trust, relevance, and other factors. If you leave multiple versions of content on a website (or websites), you might end up with a scenario like this:

If, instead, the site owner took those three pages and 301-redirected them (you can read more about how to use 301s here), the search engines would have only one, stronger page to show in the listings from that site:

When multiple pages with the potential to rank well are combined into a single page, they not only no longer compete with one another, but create a stronger relevancy and popularity signal overall. This will positively impact their ability to rank well in the search engines.
Another new option from the search engines, called the "Canonical URL Tag" is another way to reduce instances of duplicate content on a single site and canonicalize to an individual URL.
The tag is part of the HTML header on a web page, the same section you'd find the Title attribute and Meta Description tag. In fact, this tag isn't new, but like nofollow, simply uses a new rel parameter. For example:
This would tell Yahoo!, Live & Google that the page in question should be treated as though it were a copy of the URL www.seomoz.org/blog and that all of the link & content metrics the engines apply should technically flow back to that URL.
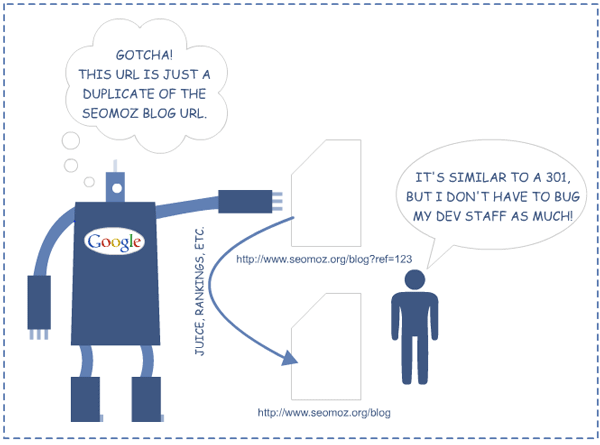
The Canonical URL tag attribute is similar in many ways to a 301 redirect from an SEO perspective. In essence, you're telling the engines that multiple pages should be considered as one (which a 301 does), without actually redirecting visitors to the new URL (often saving your dev staff considerable heartache). You can read more about implementation and specifics of the tag here.
As an example of canonicalization, SEOmoz has worked on several campaigns where two versions of every content page existed in both a standard, web version and a print-friendly version. In one instance, the publisher's own site linked to both versions, and many external links pointed to both as well (this is a common phenomenon, as bloggers & social media types like to link to print-friendly versions to avoid advertising). We worked to individually 301 re-direct all of the print-friendly versions of the content back to the originals and created a CSS option to show the page in printer-friendly format (on the same URL). This resulted in a boost of more than 20% in search engine traffic within 60 days. Not bad for a project that only required an hour to identify and a few clever rules in the htaccess file to fix.
Defending Your Rankings Against Scrapers & Spammers
Unfortunately, the web is filled with hundreds of thousands (if not millions) of unscrupulous websites whose business and traffic models depend on plucking the content of other sites and re-using them (sometimes in strangely modified ways) on their own domains. This practice of fetching your content and re-publishing is called "scraping," and the scrapers make remarkably good earnings by outranking sites for their own content and displaying ads (ironically, often Google's own AdSense program).
Preventing the scraping itself is often next to impossible, but there are good ways to protect yourself from losing out to these copycats.

First off, when you publish content in any type of feed format - RSS/XML/etc - make sure to ping the major blogging/tracking services (like Google, Technorati, Yahoo!, etc.). You can find instructions for how to ping services like Google and Technorati directly from their sites, or use a service like Pingomatic to automate the process. If your publishing software is custom-built, it's typically wise for the developer(s) to include auto-pinging upon publishing.
Next, you can use the scrapers' laziness against them. Most of the scrapers on the web will re-publish content without editing, and thus, by including links back to your site, and the specific post you've authored, you can ensure that the search engines see most of the copies linking back to you (indicating that your source is probably the originator). To do this, you'll need to use absolute, rather that relative links in your internal linking structure. Thus, rather than linking to your home page using:
<a href="../>Home</a>
You would instead use:
<a href="https://mza.bundledseo.com">Home</a>
This way, when a scraper picks up and copies the content, the link remains pointing to your site.
There are more advanced ways to protect against scraping, but none of them are entirely foolproof. You should expect that the more popular and visible your site gets, the more often you'll find your content scraped and re-published. Many times, you can ignore this problem, but if it gets very severe, and you find the scrapers taking away your rankings and traffic, you may consider using a legal process called a DMCA takedown. Luckily, SEOmoz's own in-house counsel, Sarah Bird, has authored a brilliant piece to help solve just this problem - Four Ways to Enforce Your Copyright: What to Do When Your Online Content is Being Stolen.
As always, comments, corrections, and suggestions are greatly appreciated! I'll try to speed up the guide in the next few days and weeks, so look for a little more "back to basics" blogging. I'll rely on Rebecca, Jane, & the YOUmozzers to keep adding diversity to the mix. :)
p.s. Oh jeez... 3:50am. I really need to start sleeping more.


Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.