Moz Developer Blog
Moz engineers writing about the work we do and the tech we care about.
Moz Engineering: Taking it to the next level!
Posted by Anthony Skinner on October 27, 2014
The 10-year Moz milestone has given us reason for reflection on the progress we have made in the Engineering department. When I first arrived at Moz, we had much to do in many areas:
- Monitoring: If you were with us in the early days, you know we often didn’t know if the system was down unless someone sent a tweet about it. We didn’t have monitoring, testing, or even an escalation process to call an engineer if something was broken.
- Contracting important projects: Two contractors owned products that were core to our business (such as Open Site Explorer (OSE)). Having this work done out-of-house was both risky to our core products, and all that knowledge left when we ended the contracts!
- Testing: We had a culture of not testing our systems (and no testers).
- Technology bloat: To support our complex infrastructure, we had well over 25 types of core technologies (SimpleDB, Riak, Cassandra, Erlang, Phantom.js Python, Ruby, and many more). Given our size at the time, it was one technology per person. Needless to say, we weren’t experts at all of them and it often meant if someone left, we were hosed.
- Databases but no DBA: We had large databases - several different types - with petabytes of data, but had no DBAs to support them.
- Deployment process? What deployment process?: Yeah, there was one, kind of, in place: compile your code, push it to production, and then wait to see if anyone tweeted about the system being down.
Incremental improvements
As Luke Bryan would say: “Drink a Beer!” Those days are getting farther away as we improve things day-by-day. We are steadily chipping away at what is holding us back:- Languages: Node, Python, and Ruby are the three go-to languages whenever possible.
- Databases: We’re standardizing on MySQL and HBase, but of course, are open to others. We will not sacrifice performance for the sake of standards.
- Tech Ops: We’ve grown our tech ops team, lead by Mark S, from no DBAs to two. We also now have a DevOps team dedicated to keeping the servers up and provisioned, and a team working on standardizing tools and escalation processes.
- Deployment: Changing the culture from “code and deploy” to “code, test, scale, then deploy” took effort and some buy in. However, our SDET manager, Kelsey F, has taken the reins and turning that horse around.
- Monitoring: The tech ops team has been adding monitoring, and adding more monitoring. We now actually know first when things go down. Progress!
- Testing: We have a test team now! It’s small, but scrappy! They’ve set up test environments and automation and are increasing test coverage on our products every day. They’re also helping improve quality in our other processes, like deployment, and nurturing a culture where testing happens all the time at many scopes - during and after coding, during and after scaling, during and after deploy. We are still light on SDETs, so if you know any, we are hiring.
- Work is in-house: We’ve pulled most of our development back in house, and are already seeing the benefits.
Where to go from here
At Moz, each team works as an independent unit. There are pros and cons to this arrangement. We’ll keep the pros, and are working on minimizing the cons. The largest cons we’re addressing are the barriers to sharing knowledge across groups and leveraging what others have learned, and the lack of a common framework. For us to scale and continue to improve velocity, we are focusing on building out three things:- A common application infrastructure
- An application framework
- Training and certifications
1. Create a common platform and application infrastructure
Our scale and size can be a competitive advantage, but without a functional structure in place, it becomes a plausible excuse for why everything is taking so long. Recently, I hired Arunabha to build out two parts of that structure:- An application infrastructure group to lay the foundation for our engineers to build on.
- A common platform infrastructure so devs can work across teams, not only for building applications, but also for building backend infrastructure.
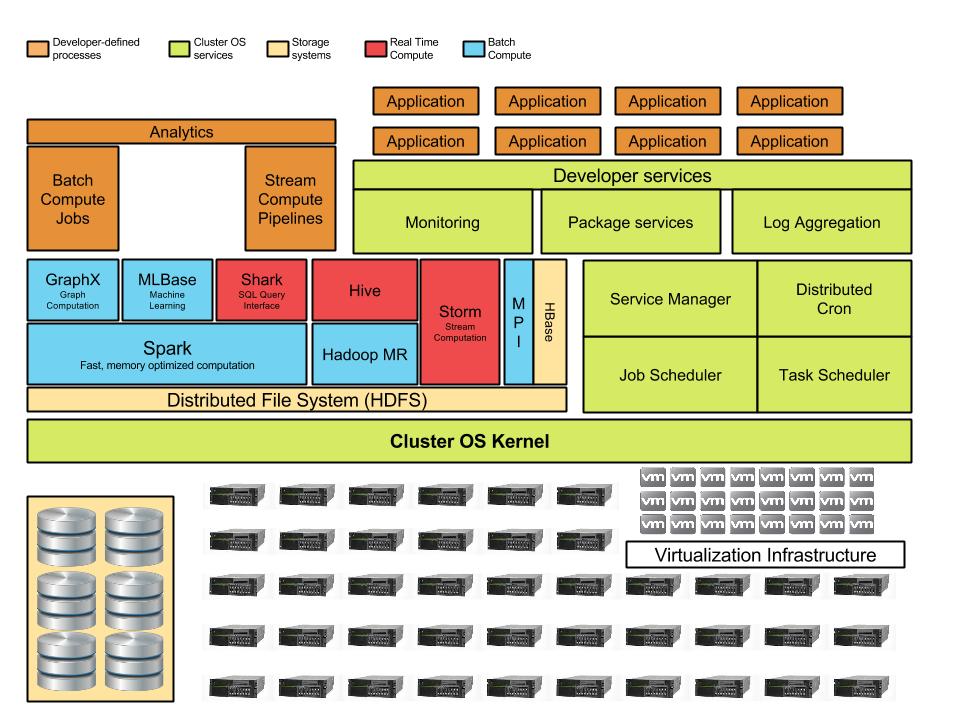 Sure, we have some fancy servers, but if it takes developers a day or two to get computing cycles for a test, it means we aren’t taking full advantage of our investment. The Roger cluster OS will let the engineers code - not wrangle hbase, deployment tools, and monitoring - while trying to get a feature out the door. With this support, they can focus on the product!
Sure, we have some fancy servers, but if it takes developers a day or two to get computing cycles for a test, it means we aren’t taking full advantage of our investment. The Roger cluster OS will let the engineers code - not wrangle hbase, deployment tools, and monitoring - while trying to get a feature out the door. With this support, they can focus on the product!
2. Build an application framework
We’ve built an internal framework called Kaleidoscope to enable rapid application development. Kaleidoscope is our second attempt. Before I arrived, we had something called the Moz Zoo that attempted to be a universal framework. Unfortunately, the name tells you how well that one worked. The Kaleidoscope framework is living up to its name too. Our Web Development team, led by Marcin, used Kaleidoscope to build the new Open Site Explorer in weeks and Link Opportunities in two days. Twist, twist, hello beautiful apps! We’ll be using Kaleidoscope going forward both to reduce development time and to bring consistency to the user interfaces and tools here at Moz.3. Roll out training and certifications
Certifying and training staff on HBase and other technologies has become critical, and I’m making it happen. While it helps to read a book or notes on the web, it is a whole other thing to be formally trained and have a group of people you can reach out to when problems come up. Once we’ve got the technology firmly in hand, our formally-trained engineering staff can train others, both at Moz and in the community.To the basics... and beyond!
Getting the basics in place has been a long, slow slog, and we have more to go. Getting buy-in from the engineers to transition to a little more formal dev process and continuous test validation has reaped many rewards. Some of the ones with the most impact are:- Defects reported by customers have gone down by 80%
- As of late, the number of off-hours pager alerts has been near nil. That’s something our engineers can really get behind!
