The Technical SEO (and Beyond) Site Audit Checklist
For SEO Agencies, Consultants, and Website Owners
A free, downloadable SEO audit spreadsheet
Can this page rank? Does it meet or exceed minimum technical SEO requirements?
These are questions asked over and over again by SEO professionals, consultants, and website owners. Seasoned professionals typically have a quick list of technical SEO items to check off when looking to solve ranking and indexing issues. Likewise, agencies and consultants often perform in-depth technical SEO audits, sometimes running hundreds of pages, to help improve the search visibility of their clients.
Here, we provide you with a free on-page technical SEO audit that's both quick and easy, and yet covers all the important areas around indexing, ranking, and visibility in Google search results based upon our years of in-depth SEO knowledge in the industry.
This audit spreadsheet is downloadable and you can modify it for your own purposes. If you're an agency or consultant, you can incorporate it into your own audit process, or if you're a website owner, you can quickly check the important SEO elements of your own site.
To get started, simply click the button below to make a copy for yourself.
If you're serious about improving your technical SEO knowledge and improving you website at the same time, we recommend reading the entire Technical SEO Checklist. We've tried to make it as concise and easy to understand as possible, and learning the basics of SEO is a vital first step in achieving your online business goals.
Go through at the pace that suits you best, and be sure to take note of the dozens of resources we link to throughout the chapters — they're also worthy of your attention.
If you want to take a more organized approach to learning technical SEO or training your entire team, check out the Moz Academy Technical SEO Certification. We've consolidated all the resources you need to learn how to confidently implement a competitive analysis strategy with unique learning strategies, task lessons and quizzes to test your knowledge. You can also display your knowledge with your Linkedin Moz SEO Essentials certification badge.
Technical SEO Certification
Learn all about technical SEO with on-demand videos and task lessons, test your knowledge with exams at the end of each section, and top it all off with shiny new credentials to share with your professional network.
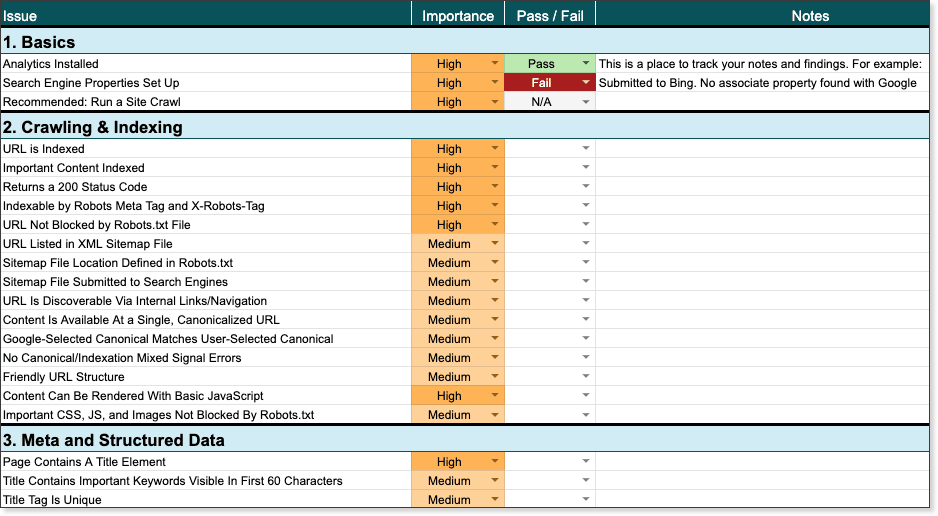
While technically not part of the audit itself, these are simple checklist items to help deliver the best data, gain access to additional tools, and in most cases, make the auditing process a hundred times easier.
Analytics installed
While having analytics installed isn't an actual ranking factor, having an analytics package can deliver a ton of visitor and technical information about your site. Most webmasters install Google Analytics, but for those with privacy or performance concerns, there exists a wealth of great alternatives.
Setting up a website property in Google Search Console or Bing Webmaster Tools (and sometimes Yandex) can provide a wealth of information about how these search engines crawl your site. Many of the additional steps in this checklist are vastly easier with access to these tools. Additionally, these tools often give you direct access to specific tools and settings which assist your site with rankings and visibility, such as sitemap submission or international targeting.
If you're auditing only a single page, nearly everything on this checklist can be audited manually by hand, using various tools and an hour or two of your time. That said, if you want to audit multiple pages at once, or scale your process, it's typically helpful to run a site crawl across your entire site.
Most major SEO toolsets offer site crawl/audit capabilities, and they can often reveal issues not uncovered via traditional analytics or Search Console properties.
Here we begin the juicy good part of the audit to answer two very basic yet important questions: are search engines crawling your site and indexing your important content?
URL is indexed
Perhaps the most important item of the entire checklist: does the URL actually appear on Google (or the search engine of your choice)? To answer this question, SEOs typically perform one of two very quick checks.
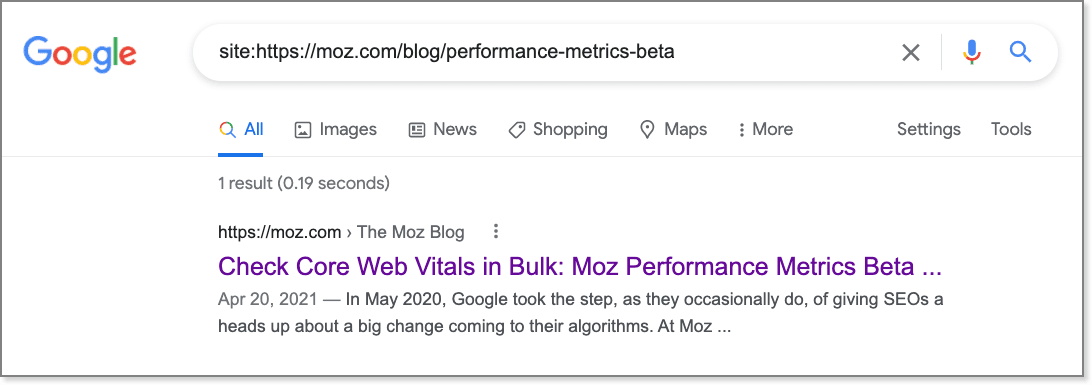
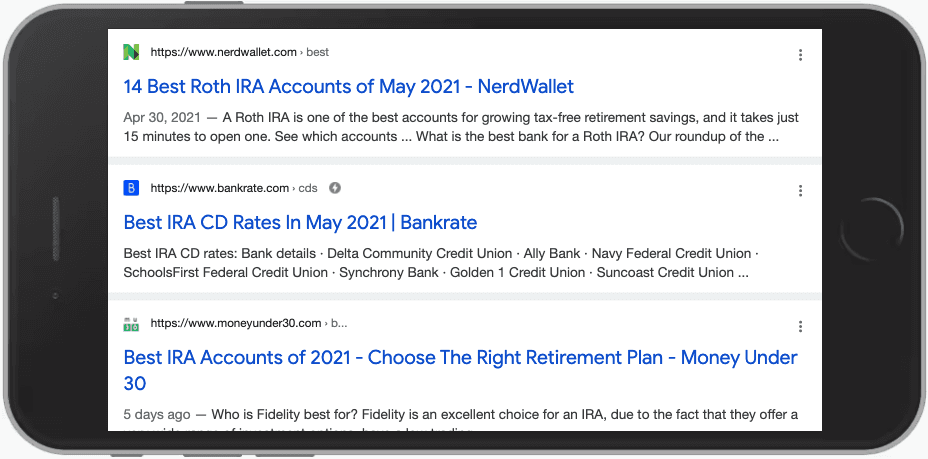
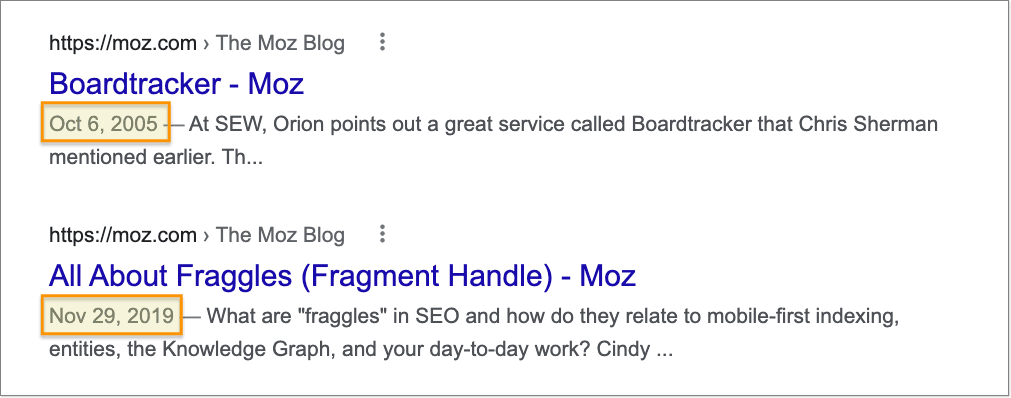
1. Do a site: search
A "site:" search is perhaps the quickest and easiest way to see if a URL is indexed. Simply type "site:" followed by the URL. For example:
The problem with using "site:" search is that it returns everything starting with the URL pattern you enter, so it can return multiple URLs that match the string. For this reason, it's often better to look up the exact URL using the URL Inspection tool in Google Search Console.
In fact, this method is preferred because the URL Inspection Tool will help you complete other audit items on this checklist.
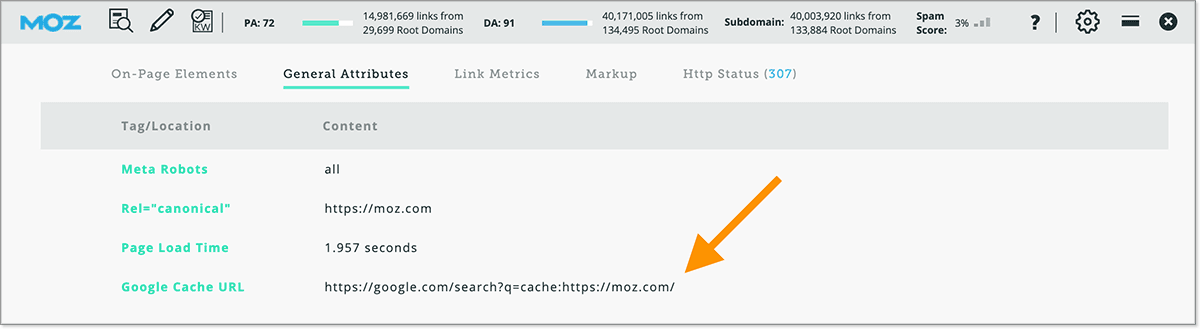
While it's important that search engines can index your URL, you also want to make sure that they can index your actual content. Although not completely foolproof, one quick way is to simply examine Google's cache of the URL. You can perform that with the following code, replacing "example.com" with your URL.
If you can't remember the code, the MozBar contains a quick link to Google's cache. It's a good idea to keep the MozBar handy, as it can help with several other items in your audit.
Note: At this point, if you've verified that your important content is indeed indexed by Google, you may not need to spend a huge amount of time digging into the indexation issues below. That said, as more pages are added at scale, these issues become increasingly important to check, and it's always good to spend a few minutes to verify.
Returns a 200 status code
At a page level, if you want search engines to index a URL, it generally needs to return a 200 HTTP response status code. Obviously, you want to avoid 4xx and 5xx errors. A 3xx redirect code is less lethal, but it typically means the URL you're auditing isn't the one that's going to rank.
If you see indexation issues, you want to do a quick check to make sure the page isn't marked with a robots "noindex" directive. A lack of a robots directive is fine, as the default is "index."
Most of the time, robots directives are placed in the HTML as a meta robots tag. Far less often, they are placed in the HTTP header as a X-robots-tag. You are free to check both places, but Google's URL Inspection report will quickly tell you if indexation is allowed.
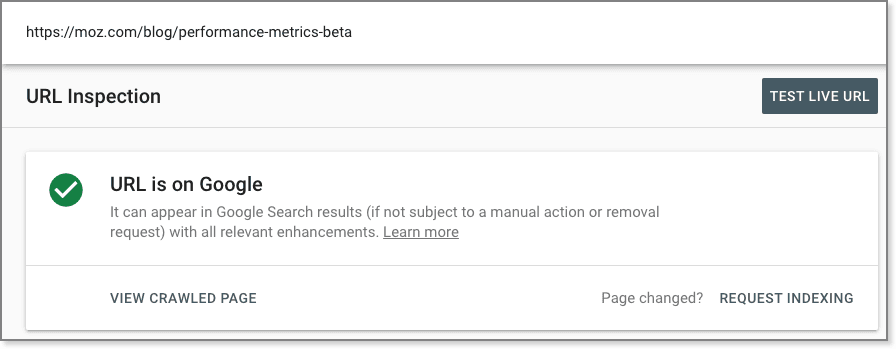
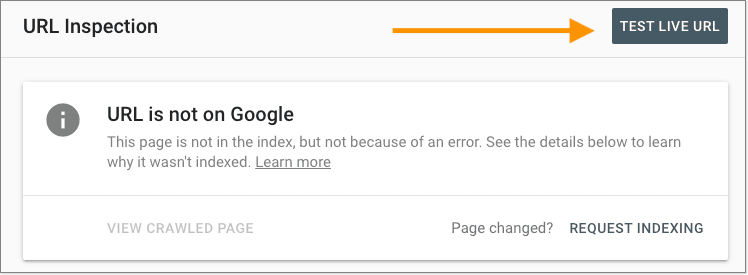
Note: If the URL is not indexed, use the "Test Live URL" in Search Console to check indexability status.
While Google can still index a URL that's blocked by robots.txt, it can't actually crawl the content on the page. And blocking via robots.txt is often enough to keep the URL out of Google's index altogether.
If the URL is simple, you might get away with a quick visual inspection of your robots.txt file. In most cases, you'll likely want to do a more thorough check of the URL using one of the tools listed below.
Technically, listing URLs in a XML sitemap file isn't required for ranking in Google, but it can make discovering your URLs by search engines a whole lot easier, and in some cases, can help with crawling and even ranking (it doesn't rank if it never gets crawled.)
Best practice is to have all your indexable URLs listed in an XML sitemap or multiple sitemap files.
Okay, so you've verified that your URL is listed in an XML sitemap. Next, you want to ensure that search engines — all search engines — can easily find your sitemap files.
The easiest and most straightforward way to accomplish this is to simply list your sitemap location in your robots.txt file. Placing your sitemap here works for all major search engines, and doesn't require any extra work. The disadvantage of this method is that it potentially exposes your sitemap to third-party crawlers, so in some cases you may not want to use it, and employ direct search engine submission (listed below) instead.
Even if your sitemap is listed in your robots.txt file, you'll still want to make sure to submit your XML sitemaps directly to search engines. This ensures that:
The search engines actually know about your XML sitemap
The search engines will report if they found the sitemaps valid
Finally, you can get a coverage report from the search engines with statistics about how they crawled and indexed the URLs found in your sitemap
Both Bing and Google support direct sitemap submission. Google offers particular value in this area because after you submit a sitemap, you can check out Google's Index Coverage Report for each individual sitemap submitted.
Sitemaps are one way search engines use to discover pages on your site, but the primary way remains by crawling webpages and following links.
Typically, your high-priority pages should be discoverable within 4–5 clicks of the homepage. This is part of your site architecture.
You also want to avoid "orphaned pages" — which are pages not linked to by any internal URLs on your site.
The process for discovering orphaned pages isn't quite so simple. SEO crawlers like Screaming Frog and Sitebulb do a decent job finding orphaned pages but require connecting to other data sources — such as sitemaps — in order to discover them. In truth, a URL that doesn't want to be found can be very difficult to find if it isn't linked to or listed anywhere.
The best way to avoid orphaned pages is to simply ensure that important pages are linked to, either via navigation or other internal links. Search Console and many SEO link tools may provide limited reporting on internal linking, but often the solution involves a more manual check.
Content is available at a single, canonicalized URL
Ah, our good friend canonicalization. We could write many, many posts on canonicalization, and we have. Suffice to say, there are a few basic guidelines you want to keep in mind when thinking about canonicalization and duplicate content.
1. All URLs should have a canonical tag
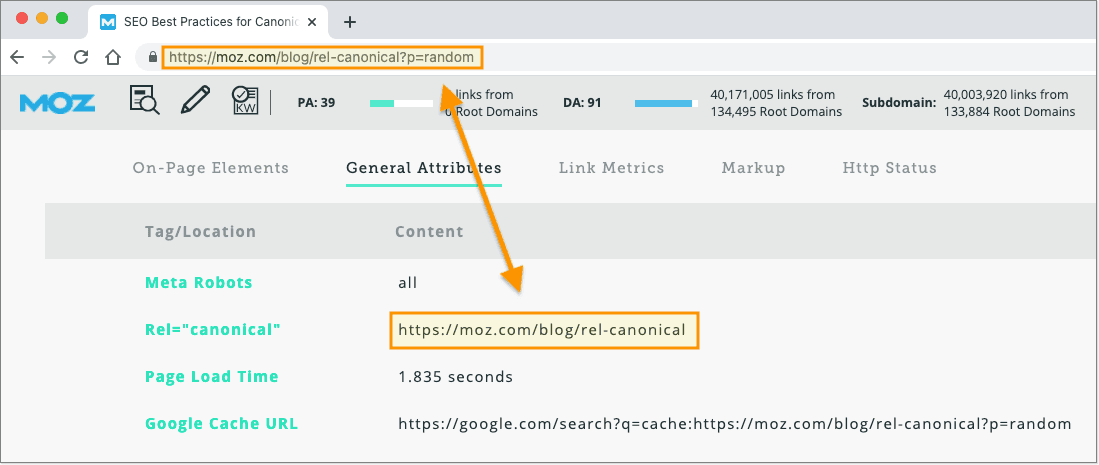
2. Different URLs with the exact same content should point to the same canonical URL. Additionally, URL parameters that don't change a page's content shouldn't change the canonical tag. For example:
Ideally, 3 out of the 4 would redirect to the "canonical" version — whichever URL pattern is correct — via 301 redirects.
You can perform a simple canonicalization check using the MozBar. Simply navigate to a URL and first verify that the page contains a self-referencing canonical. Next, try adding random parameters to the URL (ones that don't change the page content) and verify that the canonical tag doesn't change.
Note: While the most common place to signal canonicals is within the HTML, you can also place them in the HTTP header.
Here's the scary news: simply because you've defined your canonical, doesn't mean Google will respect it. Google uses many signals for canonicalization, and the actual canonical tag is only one of them. Other canonical signals Google looks at include redirects, URL patterns, links, and more.
To figure out if Google respects your user-defined canonical, Search Console is the best tool for the job. Use the Coverage Report of Search Console's URL Inspection Tool to identify instances when Google chooses a different canonical than the one you selected.
You can also find a bulk report of canonicalization errors in the "Excluded" Coverage Report, labeled "Duplicate, Google chose different canonical than user."
This one is pretty simple. You want to avoid sending mixed signals between your canonical tags and indexation tags.
For example: if Page A canonicals to Page B, and Page B is indexable, you don't want to put a "noindex" tag on Page A, as this would send mixed signals.
In short, if a URL is indexable, don't canonicalize "noindexed" pages to it.
Using shorter, human-readable URLs whenever possible
Avoiding unnecessary parameters, such as session IDs or sorting parameters
Broken relative links that cause "infinite spaces" (never-ending URLs)
It's also important to keep in mind that Google may use your URL to create breadcrumbs for your snippet in search results, so using simple, keyword-rich URLs can help with your click-through rate as well.
To learn more, Google has good documentation surrounding URL structures.
Content can be rendered with basic JavaScript
If you've made it this far, and you've already verified that Google is indeed already indexing your important content, you likely don't have any JavaScript rendering issues. That said, if you do experience a problem in these areas and your site relies on JavaScript, it may be the culprit.
The two simple tools to test if Google can render your site with basic JavaScript are Google's Mobile-Friendly Test and the "Test Live URL" function in Google's URL Inspection Tool in Search Console. Select "View Rendered Page" in Search Console to view the rendered DOM, JavaScript Console Messages, and resource loading errors.
Debugging JavaScript errors is a big subject beyond the scope of this checklist, but at least now you know where to start.
Important CSS, JS, and images not blocked by robots.txt
If search engines can't render your page, it's possible it's because your robots.txt file blocks important resources. Years ago, SEOs regularly blocked Google from crawling JavaScript files because at the time, Google didn't render much JavaScript and they felt it was a waste of crawling. Today, Google needs to access all of these files to render and "see" your page like a human.
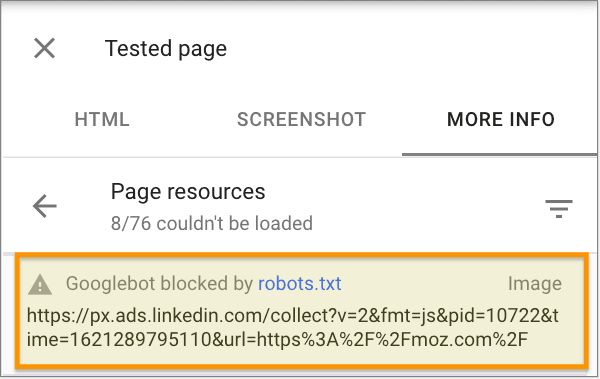
The best practice is to visually inspect your robots.txt file and make sure you don't block any important image files, CSS, or JavaScript files that would prevent search engines from rendering your page. You can also use Google's URL Inspection Tool to discover any blocked resources, as shown here.
Note: It's perfectly fine if some JavaScript or CSS is blocked by robots.txt if it's not important to render the page. Blocked third-party scripts, such as in the example above, should be no cause for concern.
Here we look at your meta and structured data — the "behind-the-scenes" information that doesn't display on the page, but may help search engines understand your content, influence how you show up in search results, and may even help you to rank higher.
Page contains a title element
Finally, an easy one!
Your URL should contain a single title tag, with text describing your page. Fortunately, missing or empty title tags are really easy to discover:
Web browsers typically display the title in the tab heading
Most SEO tools alert you to missing and/or empty title tags
You can quickly check your title using the MozBar
If your title is missing or empty, be sure to add it in!
Title contains important keywords visible in first 60 characters
A common question we get A LOT here at Moz is: "How long should my title tag be?"
The answer, of course, is it depends. Google confirms that titles can be very long. Traditionally, most SEOs recommend keeping your title to 55–60 characters, as that's the limit of what Google typically displays in search results (based on pixel length.)
Longer titles can also be problematic because they're often comprised of boiler-plate, parts of titles that repeat over and over again across different sections of your site, which Google recommends against.
Regardless of your title length, it's a good idea to keep your important keywords in the first 60 characters, where users can actually see them in search results. Keeping your important keywords in the visible part of your title can have a significant impact on click-through rates (CTR).
Whew, another point about title tags again. They must be important!
The final check of your title tag is to make sure that it's not duplicated across your site. While there's no known ranking penalty for duplicate titles, Google both encourages the use of unique titles and discourages repetitive boilerplate. Unique titles can help search engines differentiate your content, and can help identify your unique value to users.
Most SEO crawlers can easily identify duplicate title errors.
If you want to only check a single page, an easy way is to combine Google's site: and intitle: operators to search for exact match titles on your site, like this:
site:moz.com intitle:"Moz - SEO Software for Smarter Marketing"
Which gives you a result like this. Hopefully, you only see one result.
Contains unique meta description
Honestly, it sometimes can be a little hard to get enthusiastic about meta descriptions when the data shows that Google ignores our meta descriptions 63% of the time.
That said, descriptions remain important because Google will use them if they believe your description is superior to what they can pull from the page, and a good description can also help with CTR.
Because detecting duplicate descriptions isn't easy to do manually, it's typically done with an SEO crawler.
Favicon defined
A few years ago, you'd never find anything about favicons in an SEO audit. To be fair, most people still overlook them. Regardless, favicons are important because Google displays them next to your snippet in mobile search results, as in this example below.
Having a clear favicon that stands out may influence your organic CTR.
Typically, you can tell if your site has a favicon defined by simply looking at the browser tab.
To be double-sure, you want to make sure sure the favicon is defined on the homepage of your site with the following code:
To be clear: marking up your content with Open Graph and social metadata (such as Twitter cards) will not impact your Google rankings one bit. But social meta tags do influence how your content shows up on social networks such as Facebook, Pinterest, Linkedin, and more, which can influence how your content is shared, linked to, and can ultimately influence your rankings downstream.
Most modern CMS systems allow you to easily define OG and other social metadata, and even define defaults for these values, so it's best not to leave them blank.
A handy list of social debugging links we use at Moz:
These tools are often handy when you need to update a social image (or other data) and need to clear the cache to update what gets displayed on the social site.
Is structured data, by itself, a ranking factor? No.
Can structured data help me to rank? Yes, it can help Google to understand the content of your page.
Can structured data influence CTR? Yes, Google supports several types of rich snippets based on structured data.
These days, nearly every URL should have some sort of structured data that supports Google rich snippets. Whether it's as simple as article markup, identifying an author and/or an organization, product reviews, or even recipe markup, you should strive to be as clear and detailed in your structured data as possible.
While exactly how much Google uses structured data is open to debate, it's fair to say they definitely support the data types listed in their structured data Search Gallery.
To validate your structured data, try the tool below.
Here's one you won't find in most SEO audits, and it involves Google Discover.
Many SEOs have found Google Discover to be a great source of traffic, but earning the coveted spots can be elusive.
Google defines no special requirements for Google Discover inclusion, except for general advice about descriptive headlines and the use of large images. Google recommends using images at least 1200px wide, and enabled by the "max-image-preview:large" setting, which is shown in this code snippet:
Alternatively, the page can be served with AMP. To be fair, Google can likely figure out your images without this meta tag, but it's a good idea to include it nonetheless.
Now let's examine the content of the page. Many of these items don't strictly fall under the area of "technical SEO" but they can cause significant ranking issues if not addressed.
Content isn't substantially duplicate
While Google won't penalize you for duplicate content, duplicate pages typically get filtered out of search results as Google strives to "show pages with distinct information."
Small amounts of duplicate content on a page are natural and often don't present a problem, but when the majority of your content is "substantially similar" to other content found on the internet, or on your own site, it can cause issues.
While we've previously discussed solving duplicate content issues on your own site with canonicalization, noindex tags, and robots.txt control, it's also helpful to make sure you've discovered the duplicate content that exists both on your site, and possibly across the web as well.
Three different ways to find duplicate content:
Run a site crawl using the SEO tool of your choice.
For a single page, use Google's exact match search operator — by wrapping a portion of the "page text in quotes" — to find duplicate content. For example, if we search for the opening sentence to Moz's Beginner's Guide to SEO, we can see how it's been copied around the web.
While it's not uncommon to find your content duplicated across the web, it's typically not a problem, unless those sites outrank you. In these cases, you may want to file a DMCA Complaint. Even better, you can ask the offending sites to link to you as the source of the original content or add a cross-domain canonical.
Content organized with hierarchical HTML tags
Should your page use a single h1 tag? How many h2s should you use?
In reality, Google doesn't care how you organize your page, as long as you make your structure clear. Typically, this means ordering your content with headings in a hierarchical fashion. Most SEO studies show a strong relationship between the use of headings and Google rankings, so we recommend using headings to organize your content in a smart, logical way.
via Logical Content Flow
Additionally, a single h1 is still recommended for accessibility, so it's a good idea if your headline follows this rule.
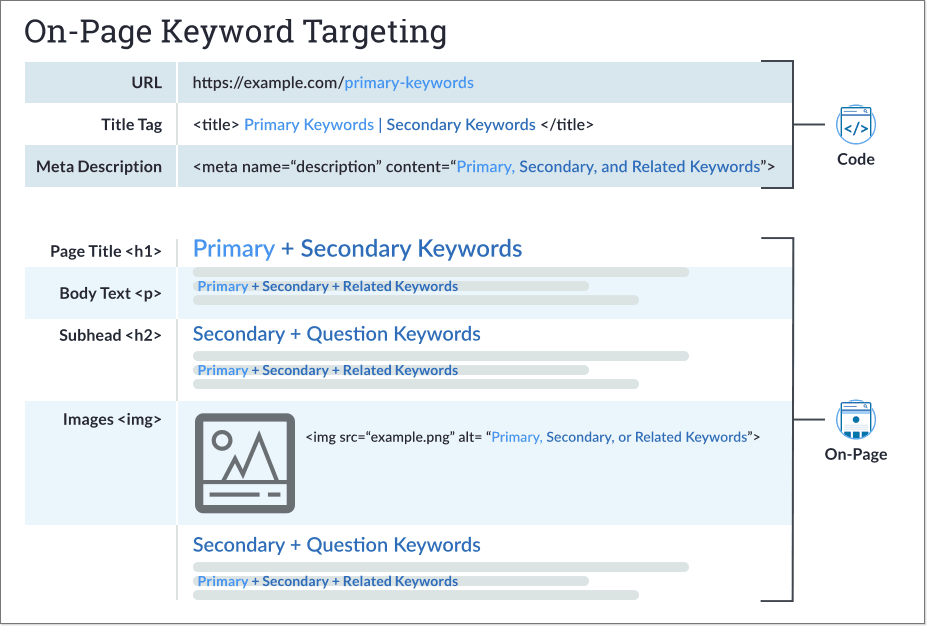
For years, keyword targeting has been the basis for many SEO site audits. While Google today is much more sophisticated about how it understands what pages are about, it's still a good idea to check that your page includes target keywords and related phrases in key places:
URL
Title tag
Meta description
Headline
Subheads
Main body text
Image alt attributes
Of course, you also want to check at this stage for keyword stuffing, and avoid it.
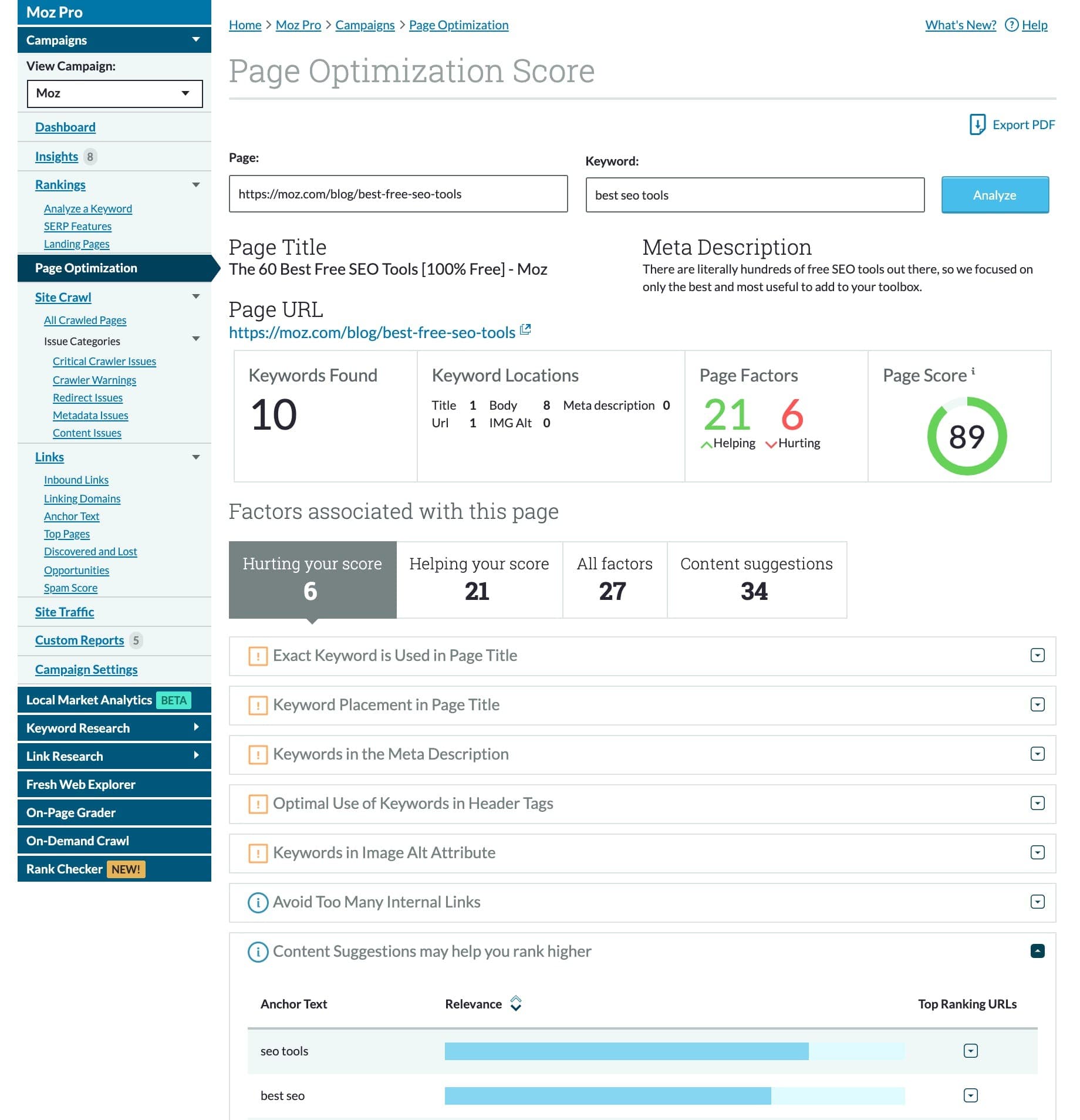
You can utilize the Page Optimization feature in Moz Pro (included as part of your 30 day free trial) to discover opportunities to optimize your pages for specific keywords, as well as see related keyword and topic suggestions. Simply navigate to the Page Optimization tab and enter the URL/keyword combo you want to rank for.
The score will change over time as you fix issues and incorporate suggestions.
Experienced SEOs can often tell at a glance if content is spammy or if it deserves a shot at ranking. As part of the audit process, it's a good idea to make sure the page meets minimum quality of standards in that it doesn't violate Google's Quality Guidelines.
Most of Google's list is obvious stuff, but worth a double-check. Things like:
Popups for legal reasons (e.g. cookie consent) and those that only take up a small amount of space typically aren't a cause for concern. That said, if your mobile URL greets you with a giant advertising banner that fills the screen, this is likely something you want to flag.
Avoids heavy ads above the fold
Heavy ads above the fold is another area that Google may penalize you for if they find the ads distract too much from your content.
Like intrusive interstitials, it's best to take a look at your page in a mobile browser to inspect how easy it is to get to your main content. If this task is made more difficult by a heavy ad presence, you likely want to mark it in your audit and experiment with reducing the top-of-page ad flow.
Content isn't loaded in an iFrame
Loading content in an iFrame can be tricky from a technical SEO point of view, and Google generally recommends against it.
Typically what happens when you use an iFrame is that Google "flattens" the iFrame with your content and considers it a part of the content itself. While this generally works, it can become problematic if the iFrame doesn't load, or Google has trouble accessing the iFrame.
In short, sometimes it's necessary or convenient to use iFrames, but you should avoid them whenever possible.
Flash is dead. If your content relies on Flash, your rankings may be dead too.
If your page still uses Flash, most browsers (including Chrome) will simply ignore it.
To audit Flash, Search Console's Mobile Usability Report will report if your site uses "incompatible plugins" including Flash.
Lazy-loaded content is visible in the ViewPort
Lazy-loading has become more popular, especially since native browser support. Many CMS frameworks, including WordPress, now incorporate lazy-loading of images by default.
When lazy-loading works correctly, images (or other content) come into view when needed in the viewport (the visible part of your web browser.) When things go wrong, content isn't loaded correctly and isn't visible to search engines.
The easiest way to audit lazy-loaded content is simply to use Google's URL Inspection Tool. After inspecting a page, check the screenshot and the HTML to make sure all images loaded correctly. For the more technical-minded, Google offers a Puppeteer script using headless Chrome.
Supports paginated loading for infinite scroll
Like lazy-loading, infinite scroll can be good for user experience, but not-so-great for search engines. When set up incorrectly, it can hide information from Google.
The correct way to implement infinite scroll is with paginated loading, which means the URL changes as the visitor scrolls down the page. You can check out an example here. This allows users to share and bookmark specific pages of your content, as well as allows search engines to index individual sections of your content. Google recommends signaling your paginated loading using the History API, which tells the browser when to update the displayed URL as the user scrolls.
Adding a publication date to your content isn't likely to impact your rankings directly, but it can have a strong influence on both your CTR and user engagement signals. Google directly displays dates in search results, which can affect user clicks.
If you choose to display dates, many SEOs choose to display the last modified or last updated date, to show readers that the content is fresh and relevant. For example, instead of saying "Published On" you could say "Last Updated" - as long as the information is true. Google knows when you actually updated your content, so you won't fool them if you try.
A few general guidelines about displaying accurate dates:
Display a visible date for the user, typically near the top of the page.
Include "datePublished" and "dateModified" properties in your Schema markup.
Keep dates consistent. For example, multiple dates on the page could confuse Google
While Google doesn't confirm authorship as a ranking factor, they do confirm tracking authorship information as entities, and working to not only determine the author of a page but also connect that author to other works on the web.
Furthermore, Google's Search Quality Rater Guidelines supports this by encouraging raters to go to great lengths to determine the reputation of the author and/or publisher. Content by anonymous or low-reputation authors/publishers is often rated "Low" quality, while content from high-reputation author/publishers is often rated "High" or "Highest."
Typically, Google can figure out who the author and publisher of a given piece are, but it's best practices to help them connect the dots. A few tips:
For specific authors, make sure the author is clearly printed on the page
Link your author to an author profile page, which in turn links to social media profiles and other articles by the same author
Include "publisher" markup in your Article Schema (or other types of schema)
Make your publisher and contact information clear on your About Us and Contact pages
Content doesn't trigger Google Safe Search filters
Millions of users use Chrome's "SafeSearch" filters, which keep explicit content, like pornography, out of their search results.
Most of the time, the system works great.
Occasionally, Google may flag a site as having explicit content, when none exists. This can sometimes happen when Google gets confused by your content.
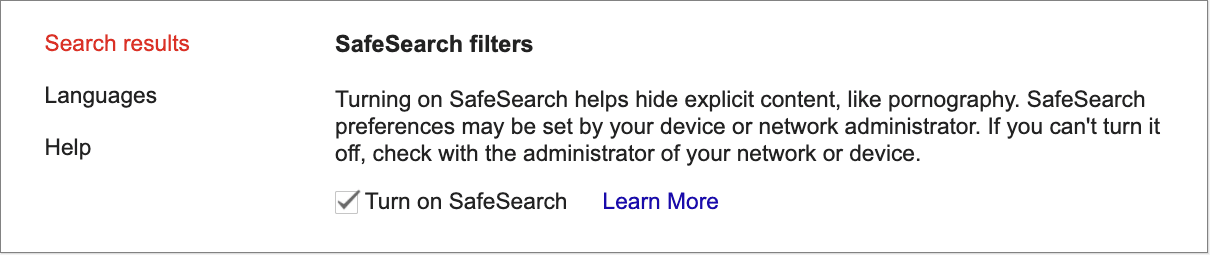
If you have any doubt at all that your site may trigger Google's SafeSearch, it's best to do a manual check:
Do a site: search of your website homepage and a few specific directories
Turn off SafeSearch and repeat the searches
If the number of results is substantially different, your site may be filtered by SafeSearch
If your site does not host adult or sensitive content and you believe SafeSearch is filtering your content in error, you can report the problem to Google.
You might be surprised, but there are many, many ways to create web links.
Some are good for SEO. Others, not so much.
In order for a link to be crawlable, search engines typically need an <a> tag with an href attribute. And yes, lots of developers create links without these attributes.
A quick way to see if your links are crawlable (and followed) is to use the MozBar to highlight all crawlable links on the page, as demonstrated below.
Pages break. The web is literally littered with 404s. It's a natural part of the ecosystem. If you happen to link to a 404, it typically doesn't represent a big SEO problem.
That said, links leading to 404s can be bad in that:
They can create a frustrating user experience
Stop the flow of link equity, e.g. PageRank
Linking to lots of 404s can be a sign that the page is outdated and unmaintained.
Fixing broken links works better when you do it at scale, and your efforts may be more greatly rewarded when you prioritize internal links. If you have a very large site, hunting down and fixing every 404 may be a low ROI effort, though the ROI rises with the importance of each page.
Most SEO crawlers can identify broken links and 404s. If you simply want to audit a single page, many Chrome extensions such as Broken Link Checker can easily handle the job.
Google uses anchor text as a ranking signal, and patent filings suggest it may even ignore links with irrelevant or generic anchor text.
Finally, Google typically frowns on "over-optimization" which can include linking with too many exact-match anchors, so it's good to mix things up.
Examples of good anchors:
"lists the best ice cream stores in Seattle"
"how to undo send in Gmail"
"our careers page"
Examples of generic anchors:
"click here"
"read more"
"example.com"
To audit the outgoing links on a single page, you can use the MozBar to highlight all internal and external links and make sure your anchor text is descriptive.
Links are qualified when appropriate (nofollow, ugc, sponsored)
Today, Google treats nofollow links as a "hint" — meaning they may in fact crawl them and count them for ranking purposes.
Google also introduced two new link attributes:
"ugc" to indicate user-generated content
"sponsored" to indicated sponsored links
These attributes, along with nofollow, can help protect you as a publisher. Since Google can penalize sites that link to spam or links that give a financial incentive, marking these links appropriately can help you avoid Google's wrath.
Faceted navigation doesn't lead to duplicate content
Faceted navigation can work great for shoppers, allowing them to narrow down their selection with nearly infinite choices.
Those same nearly infinite choices can create nearly infinite pages for Google to crawl if you aren't careful.
If every option in your faceted navigation is linked in a way that creates a new URL every time, in a way that doesn't substantively change the content, you could inadvertently create millions of duplicate or near-duplicate pages for Google to crawl.
A few best practices for faceted navigation:
Don't create clickable elements for options that don't exist or change the page content
Nofollow unimportant options and block crawling in robots.txt
Use either noindex or canonicalization for URLs you want to keep out of the index
Use Google Search Console's Parameter tool to define parameter settings.
If your site uses pagination, it's important that your paginated links are visible to search engines.
Google recently depreciated support for rel=prev/next markup, though other search engines continue to use it. This means that the primary way Google finds paginated content is through links on your page.
In general, paginated pages should be clearly linked and crawlable. Paginated pages themselves should be self-canonicalized or canonicalized to a "view all" page containing all entries.
There are lots of details and traps to fall into when dealing with pagination. If interested, we highly recommend this article by Ahref's Patrick Stox on dealing with pagination.
Page does not contain an excessive amount of links
In the old days, Google recommended no more than 100 links on a page. Those days are long gone, and today Google can process many multiples of that without challenge.
That said, even though Google can crawl several hundred links (or more) per page, there are still valid reasons to limit the number of options you present to search engines. A high number of links dilutes the link equity every link passes and can make it harder for Google to determine which links are important.
While there's no magic number as to the number of links that's reasonable, if you find every page of your site has hundreds — or thousands — of links, you may consider trimming them down to better focus your link equity and how Google crawls your site.
Finally, Google is known to devalue sitewide and/or boilerplate links, so if you have footer navigation with the same 500 links on every page, it might be valuable to experiment with new linking practices.
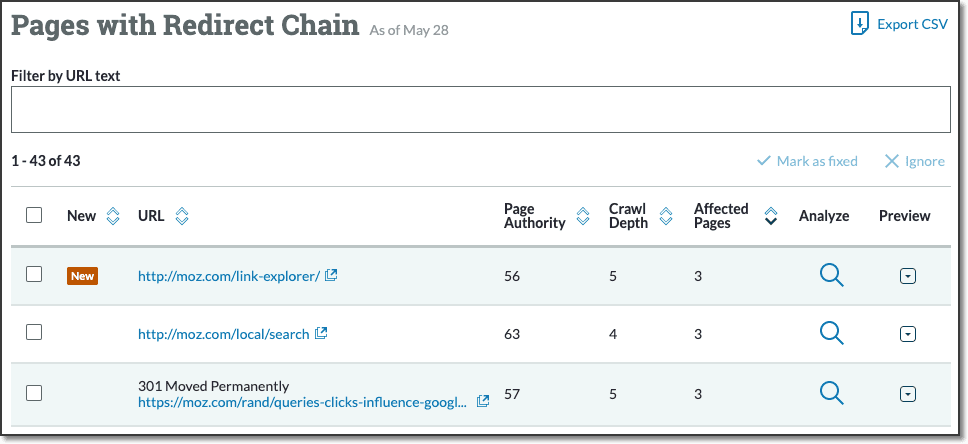
Page does not link to redirect chains
Similar to our advice about not linking to broken 404 pages, it's often helpful to check your outgoing links for redirects and redirect chains.
Pages move frequently on the web, and over time these moves can lead to redirect chains that are truly quite impressive. Google has stated they will follow up to 5 redirects per attempt — and they may make many attempts to eventually discover the final URL.
To be clear, this is typically a minor issue and one you needn't lose a lot of sleep over. Fixing redirect chains reduces the chance of crawling errors and, as such, can help preserve link equity. On the other hand, a small number of 3xx redirects is completely normal, and fixing these likely won't produce large gains.
Pinpoint technical site issues
Run a free Site Crawl Audit with your 30-day free trial of Moz Pro.
Execute a Technical SEO Audit Like a Pro [Webinar]
Join Moz's SEO Manager, Kavi Kardos, to discover tactics you'll employ to make your site more efficient, effective, and enjoyable to use. She'll break down the major aspects of technical SEO — crawling, indexation, site performance, and accessibility — with the help of our Site Audit checklist.
Did you know that if Google's image search was its own search engine, it would account for over 20% of the total search engine market share?
Regardless, ranking in image search isn't the only reason to optimize your images, as images can play an important part in your overall SEO.
Images contain descriptive alt attributes
Generally, images need alt attributes for 3 primary reasons:
Alt attributes help search engines to understand the image
For images that link to another URL, the alt attribute acts as the link's anchor text
Accessibility: screen readers and other applications rely on alt text to properly understand the page
To be fair, fixing a missing alt text or two (or three) likely isn't going to move the SEO needle very much, but at scale and when applied consistently, descriptive alt text can help Google add content to your page and imagery, as well as help you rank.
Keep your alt text concise but descriptive. The best alt texts are those that would make the most sense to one using a screen reader who couldn't actually see the picture.
While defining image heights and widths isn't a direct Google ranking factor, the lack of image dimensions can cause usability issues as a browser tries to load the page.
Because layout shift is really the important issue here, it's best to run a speed audit of your site using something like Google's Page Speed Insights, and see what your CLS score reflects. If it's low, there's a good chance you have images without defined dimensions.
There are many ways to define image dimensions. For a good overview, we recommend this article at web.dev.
Use descriptive titles, captions, filenames, and text for images
In addition to alt text, Google uses many other signals to determine what an image is about, and how it relates to your content. These signals include:
Image title
Captions
Filenames
Text surrounding the image
Ideally, and for maximum visibility, each of these elements is defined, descriptive, and unique.
Most of the time, the #1 element folks neglect is the filename. A human-readable filename, one that ideally uses descriptive keywords, is the way to go.
While Google has gotten much better at understanding text embedded in images in recent years, you still shouldn't rely on them to index any image text on your page.
An all-too-common mistake is for inexperienced web designers to place text in images, without understanding that the text is nearly invisible to search engines.
If your images do contain important text, make sure that the same information is communicated either in the alt text, captions, titles, or surrounding body text.
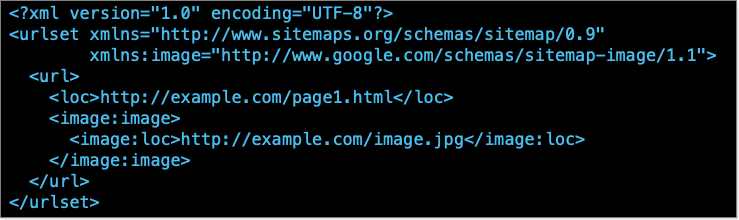
Images are listed in image sitemaps
For better discoverability and indexing by search engines, it's helpful to list images in a sitemap file, or an image sitemap file specifically for images, which might look like this:
A few things to note about image sitemaps:
Unlike regular sitemap URLs, image sitemap URLs can be on another domain entirely, which allows for CDNs.
Each URL entry can list up to 1,000 images.
Image sitemaps can contain a number of optional entries such as caption, title, license, and geo-location.
Some days, it may seem like YouTube is the only game in town, but Google does index and rank videos from millions of different sites. For maximum visibility, there are a few best practices you'll want to follow.
Video is available on a public, indexable page
This is kind of a no-brainer, but it's not always obvious. Google doesn't rank videos by themselves but instead ranks your pages that actually host the video where they are embedded.
This means that the video needs to appear on a public, indexable URL.
Additionally, the URL of the video itself must be accessible by Google on a stable URL, not blocked by robots.txt or any other means.
For example, you can directly access one of our Whiteboard Friday videos here. It's a stable URL that Google can access, but it's not a publicly indexable page. On the other hand, our actual Whiteboard Friday page that embeds the video is both public and indexable, so this is the page that Google would rank.
Video is wrapped within an appropriate HTML tag
A small but simple point: when you embed your video, make sure Google can identify it as a video by wrapping it in an appropriate HTML tag. Acceptable tags are:
<video>
<embed>
<iframe>
<object>
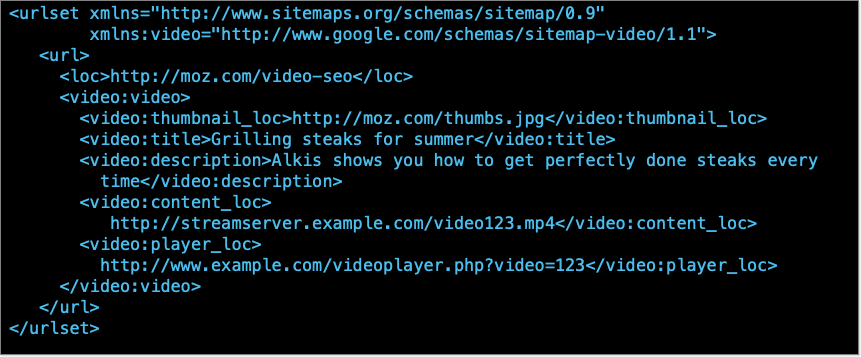
Videos is included in video sitemap
While video sitemaps aren't strictly required if you also use video schema markup, they can be hugely beneficial in helping search engines both find your videos and understand related information about your videos included in the sitemap.
Video sitemaps are valuable because, in order to be indexed and ranked, it's helpful to explicitly define additional information about your videos, such as the video location, title, description, and thumbnail.
To be clear, these properties should be defined in either a video sitemap file or on-page schema markup. Ideally, you would define this information in both places, as each offers its own unique advantages.
Required properties that you must define in your video sitemap:
<url> - Parent tag
<loc> - URL where you host the video
<video:video> - Parent tag for video information
<video:thumbnail_loc> - URL of the video thumbnail
<video:title> - Title of the video
<video:description> - Description of the video
<video:content_loc> - URL of the actual video file
<video:player_loc> - Alternate to <video:content_loc> if you want to list a video player URL instead.
There are multiple other optional properties as well, including view counts, ratings, and more.
Adding video schema is important because, like video sitemaps, your structured data provides information typically considered as necessary for Google to display your video in search results. Required properties include:
description
name
thumbnailUrl
uploadDate
Beyond these required properties, video schema allows you to add several other data points to influence how your video appears in search.
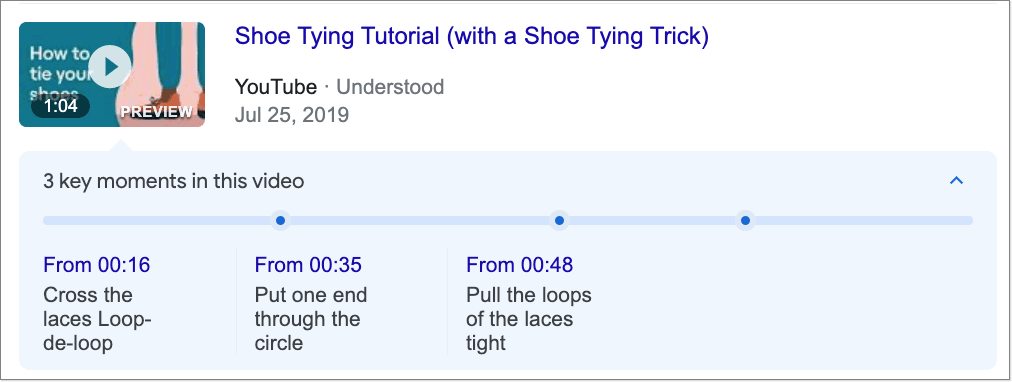
Adding BroadcastEvent markup can make your video eligible for Google's "Live" badge when applicable. Google also allows you to define Key Moments, which are increasing in popularity, by using Clip or SeekToAction Schema. If using YouTube, you can specify timestamps for Key Moments manually.
In the age of Google's mobile-first indexing, it seems very few sites remain that are not mobile-friendly. Regardless, there are a number of best practices that still trip up websites that can hurt visibility in search results.
Passes Google Mobile-Friendly Test
Pure and simple, you want to know if your site passes Google's Mobile-Friendly Test. Sites that do not meet Google's mobile-friendly criteria are likely not to rank as well in mobile search results.
You can find the same information in Search Console's Mobile Usability Report. If a page fails the mobile-friendly test, each report flags which issues need to be fixed, such as setting the viewport width, or content wider than the screen.
Preference responsive web design
When building a mobile experience for your website, you typically have three different options:
Responsive web design: Serves the same content from the same URL on both mobile and desktop, but the layout changes based on screen size.
Dynamic serving: Similar to responsive web design in that the URL stays the same, but the content itself may change based on which device the browser detects.
Separate URLs: With separate URLs, the mobile version is served from a completely different URL (often referred to as an m.site). Users are typically redirected to the right version based on their device.
While each of these methods is valid, one is strongly preferred above the others: responsive web design. The advantages of responsive web design are numerous, including a single URL, content that doesn't change by device, no need for redirection, less chance for content errors, easier to maintain, and it allows Google to crawl only a single page.
If your site uses one of the other methods, you can still rank, but you'll have to do more work to signal your mobile pages to Google. You should strongly preference responsive web design whenever possible.
Mobile content and links match desktop site
By far, the biggest technical mistake with mobile SEO is when mobile content doesn't match desktop content. If Google has turned on mobile-first indexing for your site (as it has for the vast majority of websites) this means any content that's "missing" on the mobile version of your site may not get indexed as it would on desktop.
Content checks that should be the same on both the mobile and desktop versions of your site include:
Meta robots tags (e.g. index, nofollow)
Title tags and metadata
Content
Heading tags
Images
Links
Structured data
robots.txt access
You can easily check for differences in these areas using the tools below.
In some situations, your site may separate URLs to serve mobile pages (again, not recommended). For instance, example.com might serve desktop users, but redirect to m.example.com for mobile users.
The best practices above around keeping your content and links the same on both versions of your site still apply, but if you use an m.site to serve mobile pages, keep in mind these key differences:
1. Canonicalization: Mobile pages on a separate URL should not canonicalize to themselves, but rather to the desktop version of the page, as so:
<link rel="canonical" href="http://moz.com/">
At the same time, the desktop version should canonical to itself as normal, but should also signal to Google the existence of a mobile page, using rel="alternate"
<link rel="alternate" media="only screen and (max-width: 640px)"
href="http://m.moz.com/">
2. Internationalization (hreflang): Unlike other elements that should be the same between your mobile and desktop URLs, if you use hreflang attributes for internationalization, you should link between your mobile and desktop URLs separately.
This means your mobile hreflang tags should point to other mobile URLs, while your desktop hreflang tags should point to your desktop URLs. Mixing the two could lead to mixed signals, causing indexation and ranking issues.
Speed has played a role in search engine ranking factors for many years, and now with Google's Core Web Vitals update, it's top of mind for many SEOs.
At this point, you might expect to find a 28-point web speed checklist, but that's simply not the case. Speed is not a one-size-fits-all technical SEO challenge. A single-page site with minimal JavaScript will have very different speed issues than a complex e-commerce site with lots of different technology.
Simply put, if your site is already fast, you likely don't need to worry about much — your investigation should uncover exactly what needs to be fixed. We'll cover the basics here.
Content fully loads within a reasonable time
Our first recommendation seems paradoxically non-technical but provides a good starting point from a real user point of view. Does your site load fast, or do users experience painful slowness?
The challenge of any speed audit is that every tool provides you with a different score. For this reason, a decent baseline measurement is total load time. This simply measures the total time it takes your content to load in the browser. While this measurement is too basic for a full picture of your speed performance, it can give you a rough idea if your site is fast or slow, or somewhere in between.
While there's no set benchmark for average load time, 4–5 seconds is typically a reasonable goal to hit. If your pages take longer than this, speed is an area that's likely costing you traffic and visitor satisfaction.
URL passes Google's Core Web Vitals assessment
As Google has evolved its use of speed as a ranking factor, today the most direct route of auditing your site for speed is to measure against Core Web Vitals.
There are many, many ways to measure your CWV scores. A few of the most common:
Keep in mind that you don't need a "good" score in every metric to see a rankings boost. Even small improvements may help you. Also keep in mind that Google weights speed as a "minor" ranking factor, often describing it as a "tie-breaker." That said, speed is hugely important to users, and typically influences engagement metrics such as bounce rate.
Finally, remember that you'll typically see two sets of Core Web Vital scores for every URL: one for desktop, another for mobile. This is important because presently, Google's ranking boost to pages with good CWV scores is planned only for mobile rankings (though it's still a good idea to optimize your desktop experience as well.)
Address common speed traps
Auditing Core Web Vitals can prove a little confusing, as sitewide issues and best practices can be obscured when auditing at the page level. Regardless of your CWV scores, there are a few best practices that broadly apply to many websites, and addressing these issues may help you to avoid common "speed traps."
While this list is not exhaustive, if your site needs improvement, finding which areas to address may definitely help.
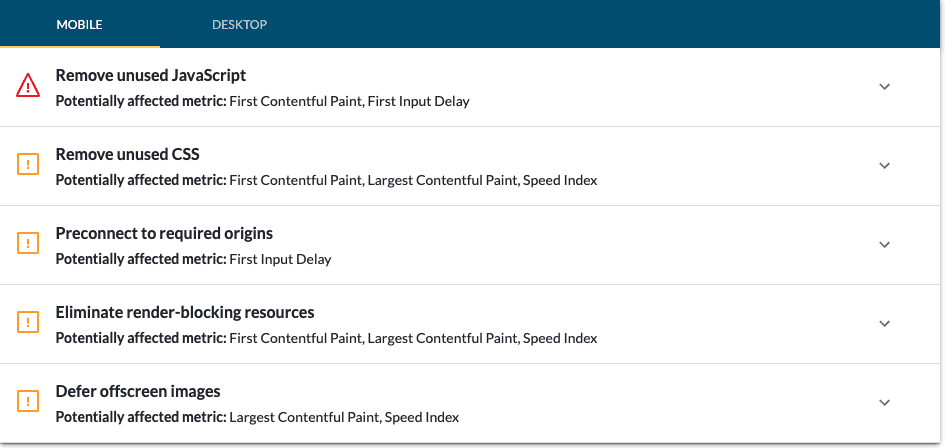
1. Image optimization
By far, one of the largest contributors to slow websites is images. Making sure your image files aren't too large often makes all the difference.
Additionally, Google's documentation recommends several other image optimization techniques, including:
We recommend using Gzip, a software application for file compression, to reduce the size of your CSS, HTML, and JavaScript files for faster serving.
3. Optimize CSS and JavaScript
By far, both CSS and JavaScript are two of the things with the most potential to slow down your site, especially if the server needs to download and execute the files. Specifically, Google recommends the following optimizations:
Fixing your response time may be easier said than done. First, it's important to identify the bottlenecks that may be slowing you down. Common culprits could be your server, database, CMS, themes, plugins, and more.
For WordPress users, Cloudflare offers an interesting solution for reducing Time to First Byte you might consider. Otherwise, Google offers a few best practices as well.
5. Leverage browser caching
Browsers cache a lot of information (stylesheets, images, JavaScript files, and more) so that when a visitor comes back to your site, the browser doesn't have to reload the entire page. You can set your Cache-Control for how long you want that information to be cached. Google has more information about leveraging caching here.
6. Use a Content Distribution Network
While it's not directly addressed in Core Web Vital audits, using a Content Distribution Network (CDN) can help address many real-world speed issues for actual users. CDNs speed up your site by storing your files at locations around the world and speeding up the delivery of those assets when users request them.
There are literally hundreds of CDNs you can use. A few of the more popular ones include Cloudflare, Fastly, and more.
Pro tip: Check your Core Web Vitals in bulk
Analyze the Core Web Vitals score for URLs of your choosing by crawling up to 6,000 pages per campaign with Moz Pro.
Security issues aren't typically the first thing one thinks about when doing a technical SEO audit, but security issues can definitely tank your rankings if not addressed. Fortunately, there are a few checks you can make to ensure your site is up to par.
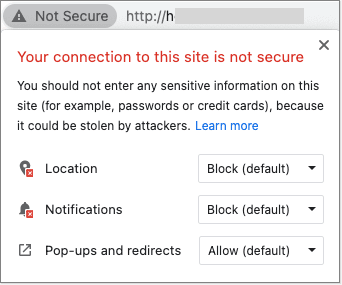
Site Uses Proper HTTPS
Yes, the use of HTTPS is an official Google ranking signal. Technically, it's a small signal and classified as a "tie-breaker." That said, recent browser updates and user expectations mean that HTTPS is table stakes on today's web.
Auditing SSL/HTTPS is easy, as most browsers will simply warn you when you try to visit a site that isn't encrypted. Make sure to access the site at HTTP (without the "S") if no redirects are in place.
Today, setting up a site with HTTPS is fairly straightforward with tools like Let's Encrypt and ZeroSSL.
Site supports HSTS
HSTS stands for HTTP Strict Transport Security. While there's no indication that HSTS is a ranking signal, Google recommends using it nonetheless because it can increase the security of your website.
Basically, HSTS instructs the user's browser to always load pages over HTTPS automatically, no matter the protocol entered.
To enable HSTS, you must serve a Strict-Transport-Security response header with a max-age directive in seconds, like so:
Strict-Transport-Security => max-age=2592000
To ensure HSTS doesn't cause problems for visitors, it's typically best to start with a low max-age, and work your way up to a year, or 31,536,000 seconds.
If your site meets other requirements, you can submit your site for inclusion in Chrome's HSTS preload list, which tells most browsers ahead of time to load your site via HTTPS only. This can lead to benefits in both performance and security.
For the average webmaster, this can be a lot to take in, so don't worry if it's too overwhelming! And if you want to check your HTTP headers, you can use a tool such as httpstatus.io.
No hacked content, malware, or other security issues
In most cases, if your site suffers from hacked content or security issues, it's typically easy to spot for a couple of reasons:
If you have Google Search Console set up, Google will typically notify you in-app in addition to emailing you.
Major browsers, including Chrome, will likely show a warning to visitors if they try to access your site.
If you see a sudden drop-off in traffic you can't account for, it's worth a quick check for these security issues.
While Search Console catches a lot of hacked content, it doesn't catch everything. If you suspect your site has been injected with spam or another type of attack, you may want to use a third-party security tool to run a quick check for major issues.
Finally, if you don't have access to Search Console, you can simply try navigating to your site using Chrome (incognito is best) to look for any security warnings. Alternatively, you can check your site status using Google's Safe Browsing tool.
11. International & multilingual sites
Millions of sites target different languages and geographical areas all over the globe. If your site targets multiple regions and/or languages with variations of your content, you'll want to do a thorough check for language and geotargeting accuracy.
Signal location targeting
If your content targets specific locations, or multiple locations, there are three primary ways to signal this to Google:
1. Local-specific URLs. For example, Google would interpret the following URLs to primarily target users in Australia:
au.example.com (subdomain)
example.au (top-level domain)
example.com/au (directory)
Not recommended are parameters to specify geotargeting, such as example.com?loc=au.
2. hreflang attributes. There are three different places you can specify hreflang targeting:
3. International Targeting Report. Using Google Search Console, you can use the International Targeting Report to target your entire site to a specific country. This option is not recommended if your site targets multiple areas.
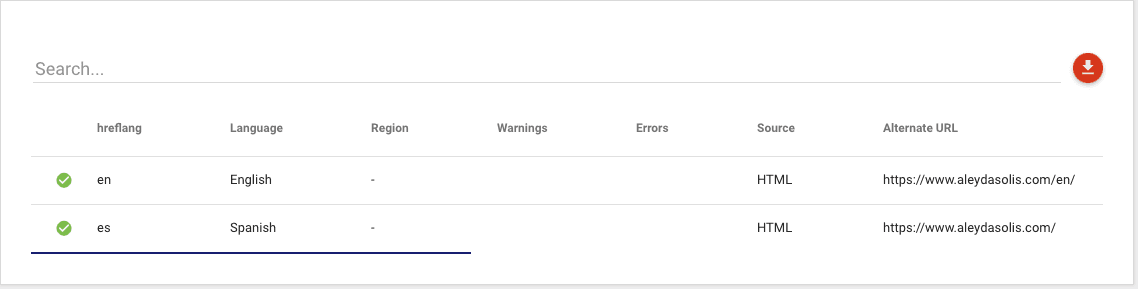
Valid hreflang annotation
Most sites that target multiple geographical or language variations use hreflang attributes, either in the HTML, the HTTP headers, or via a sitemap file.
The rules for valid hreflang are complex, and they are very easy for even the most experienced SEO to mess up badly. This is probably one of the reasons Google only considers hreflang a "hint" for ranking and targeting purposes.
As we stated, Google considers hreflang a "hint" when targeting content towards a specific audience, combining it with many other hints, including the language of the page.
For this reason, your page language should be obvious. Mixed languages on a page can send mixed signals.
If you load a page in Chrome and Google offers to translate from a language that isn't obvious, you may be sending mixed language signals. Often, eliminating boilerplate text or navigational elements may solve the problem, or simply adding more content in the appropriate language.
Avoid automatic redirection
By far one of the biggest mistakes websites make with language and geolocation targeting is automatic redirection. It's common for websites to detect a user's location via their IP or other information, and then attempt to automatically redirect them to the "correct" page for simplicity's sake.
Unfortunately, this is bad practice.
Automatic redirection can hide content from both users and Google. If Google itself is automatically redirected, it may never crawl all of your content.
Instead, first prioritize getting Google to serve the correct page to users by using the signals above. Second, as a fallback, use hyperlinks to allow users to select the correct language/location for themselves. The additional benefit of using hyperlinks is that when combined with proper hreflang markup, they could actually increase Google's crawl coverage of your URLs.
Perform a free Site Crawl Audit with Moz Pro
Pinpoint technical site issues and see a list of fixes with a 30-day free trial of Moz Pro.
If we're being honest, backlinks aren't typically included in most technical SEO audits. The truth is, most SEO audits are performed to ensure a page has the maximum potential to rank, but one of the primary reasons a page may not rank is because of a lack of backlinks.
So if we've made it this far to ensure our site is technically tip-top, we should take a few extra steps to make sure our backlinks are in order.
While there are many techniques to find and audit backlinks, at a minimum you want to ensure your page has a mix of links from trusted external sources and internal pages with a variety of anchor text phrases that accurately describe your content.
In the old days, SEOs had to worry about backlinks... a lot. Google's Penguin algorithm was designed, in part, to demote (or at least not reward) sites with a spammy backlink profile.
That said, if Google determines you've violated their policies on manipulative link building, they may still issue a manual penalty, or possibly demote you algorithmically in search results.
Regardless, when performing an SEO audit, you should perform a couple of quick checks:
Does the website have any manual actions listed in Google Search Console?
Has the site participated in actions that knowingly violate Google's guidelines against manipulative link building?
To be clear: the vast majority of sites do not need to disavow links.
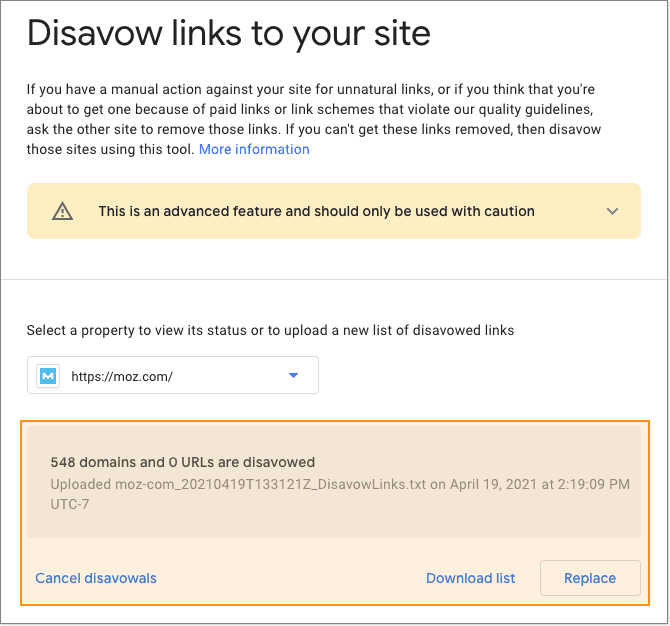
Regardless, you should still check the site's disavow file.
Many sites contain old disavow files without even being aware of them. Other SEOs, agencies, or website owners may have inserted blanket disavow rules, intentionally or unintentionally. Without manually checking the file, you have no idea if you may be blocking important links.
To perform this check, simply head to Google's Disavow Tool and see if any disavow files exist. You may need to check each property separately, as domain properties aren't supported.
If a file does exist, download it and make sure you aren't blocking any important links to your site. If so, you can re-upload a new list, or optionally, cancel the disavow file entirely.
While the benefits of removing links from the disavow tool are debated in the SEO community, there is anecdotal evidence from several sources that it can help in certain circumstances. At the very minimum, you should know what's in your disavow file.
Next Steps
Congrats! You've completed your technical SEO (and beyond) site audit.
If you're new to SEO, it might have taken a while to get through the list. With practice, you should be able to complete a small audit like this in only a few hours.
Over time, you may want to modify this audit to suit your needs, or dress it up with your company's own branding to present to clients (you have our permission!)