

Panda 4.1: The Devil Is in the Aggregate
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
I wish I didn't have to say this. I wish I could look in the eyes of every victim of the last Panda 4.1 update and tell them it was something new, something unforeseeable, something out of their control. I wish I could tell them that Google pulled a fast one that no one saw coming. But I can't.
Like many in the industry, I have been studying Panda closely since its inception. Google gave us a rare glimpse behind the curtain by providing us with the very guidelines they set in place to build their massive machine-learned algorithm which came to be known as Panda. Three and a half years later, Panda is still with us and seems to still catch us off guard. Enough is enough.
What I intend to show you throughout this piece is that the original Panda questionnaire still remains a powerful predictive tool to wield in defense of what can be a painful organic traffic loss. By analyzing the winner/loser reports of Panda 4.1 using standard Panda surveys, we can determine whether Google's choices are still in line with their original vision. So let's dive in.
The process
The first thing we need to do is acquire a winners and losers list. I picked this excellent one from SearchMetrics although any list would do as long as it is accurate. Second, I proceeded to run a Panda questionnaire with 10 questions on random pages from each of the sites (both the winners and losers). You can run your own Panda survey by following Distilled and Moz's instructions here or just use PandaRisk like I did. After completing these analyses, we simply compare the scores across the board to determine whether they continue to reflect what we would expect given the original goals of the Panda algorithm.
The aggregate results
I actually want to do this a little bit backwards to drive home a point. Normally we would build to the aggregate results, starting with the details and leaving you with the big picture. But Panda is a big-picture kind of algorithmic update. It is specially focused on the intersection of myriad features, the sum is greater than the parts. While breaking down these features can give us some insight, at the end of the day we need to stay acutely aware that unless we do well across the board, we are at risk.
Below is a graph of the average cumulative scores across the winners and losers. The top row are winners, the bottom row are losers. The left and right red circles indicate the lowest and highest scores within those categories, and the blue circle represents the average. There is something very important that I want to point out on this graph. The highest individual average score of all the losers is less than the lowest average score of the winners. This means that in our randomly selected data set, not a single loser averaged as high a score as the worst winner. When we aggregate the data together, even with a crude system of averages rather than the far more sophisticated machine learning techniques employed by Google, there is a clear disparity between the sites that survive Panda and those that do not.

It is also worth pointing out here that there is no positive Panda algorithm to our knowledge. Sites that perform well on Panda do not see boosts because they are being given ranking preference by Google, rather their competitors have seen rankings loss or their own previous Panda penalties have been lifted. In either scenario, we should remember that performing well on Panda assessments isn't going to necessarily increase your rankings, but it should help you sustain them.
Now, let's move on to some of the individual questions. We are going to start with the least correlated questions and move to those which most strongly correlate with performance in Panda 4.1. While all of the questions had positive correlations, a few lacked statistical significance.
Insignificant correlation
The first question which was not statistically significant in its correlation with Panda performance was "This page has visible errors on it". The scores have been inverted here so that the higher the score, the fewer the number of people who reported that the page has errors. You can see that while more respondents did say that the winners had no visible errors, the difference was very slight. In fact, there was only a 5.35% difference between the two. I will save comment on this until after we discuss the next question.
 The second question which was not statistically significant in its correlation with Panda performance was "This page has too many ads". The scores have once again been inverted here so that the higher the score, the fewer the number of people who reported that the page has too many ads. This was even closer. The winners performed only 2.3% better than the losers in Panda 4.1.
The second question which was not statistically significant in its correlation with Panda performance was "This page has too many ads". The scores have once again been inverted here so that the higher the score, the fewer the number of people who reported that the page has too many ads. This was even closer. The winners performed only 2.3% better than the losers in Panda 4.1.
 I think there is a clear takeaway from these two questions. Nearly everyone gets the easy stuff right, but that isn't enough. First, a lot of pages just have no ads whatsoever because that isn't their business model. Even those that do have ads have caught on for the most part and optimized their pages accordingly, especially given that Google has other layout algorithms in place aside from Panda. Moreover, content inaccuracy is more likely to impact scrapers and content spinners than most sites, so it is unsurprising that few if any reported that the pages were filled with errors. If you score poorly on either of these, you have only begun to scratch the surface, because most websites get these right enough.
I think there is a clear takeaway from these two questions. Nearly everyone gets the easy stuff right, but that isn't enough. First, a lot of pages just have no ads whatsoever because that isn't their business model. Even those that do have ads have caught on for the most part and optimized their pages accordingly, especially given that Google has other layout algorithms in place aside from Panda. Moreover, content inaccuracy is more likely to impact scrapers and content spinners than most sites, so it is unsurprising that few if any reported that the pages were filled with errors. If you score poorly on either of these, you have only begun to scratch the surface, because most websites get these right enough.
Moderate correlation
A number of Panda questions drew statistically significant difference in means but there was still substantial crossover between the winners and losers. Whenever the average of the losers was greater than the lowest of the winners, I considered it only a moderate correlation. While the difference between means remained strong, there was still a good deal of variance in the scores.
The first of these to consider was the question as to whether the content was "trustworthy". You will notice a trend in a lot of these questions that there is a great deal of subjective human opinion. This subjectivity plays itself out quite a bit when the topics of the site might deal with very different categories of knowledge. For example, a celebrity fact site might be very trustworthy (although the site might be ad-laden) and an opinion piece in the New Yorker on the same celebrity might not be seen as trustworthy - even though it is plainly labeled as opinion. The trustworthy question ties back to the "does this page have errors" question quite nicely, drawing attention to the difference between a subjective and objective question and the way it can spread the means out nicely when you ask a respondent to give more of a personal opinion. This might seem unfair, but in the real world your site and Google itself is being judged by that subjective opinion, so it is understandable why Google wants to get at it algorithmically. Nevertheless, there was a strong difference in means between winners and losers of 12.57%, more than double the difference we saw between winners and losers on the question of Errors.

Original content has long been a known requirement of organic search success, so no one was surprised when it made its way into the Panda questionnaire. It still remains an influential piece of the puzzle with a difference in mean of nearly 20%. It was barely ruled out from being a heavily correlated feature due to one loser edging out a loss against the losers' average mean. Notice though that one of the winners scored a perfect 100% on the survey. This perfect score was received despite hundreds of respondents. It can be done.

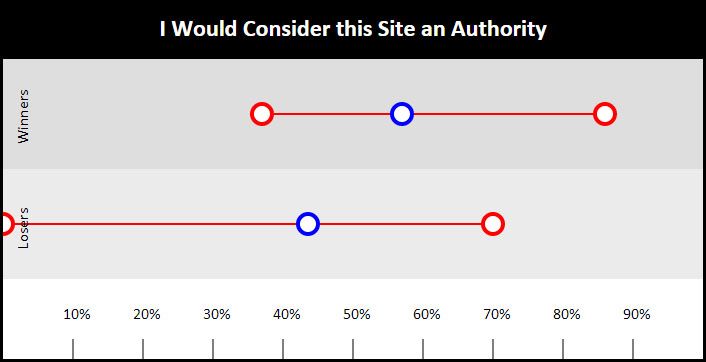
As you can imagine, perception on what is and is not an authority is very subjective. This question is powerful because it pulls in all kinds of assumptions and presuppositions about brand, subject matter, content quality, design, justification, citations, etc. This likely explains why this question is beleaguered by one of the highest variances on the survey. Nevertheless, there was a 13.42% difference in means. And, on the other side of the scale, we did see what it is like to have a site that is clearly not an authority, scoring the worst possible 0% on this question. This is what happens when you include highly irrelevant content on your site just for the purpose of picking up either links or traffic. Be wary.
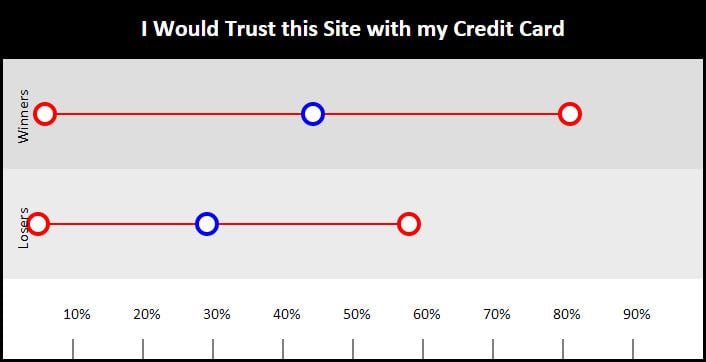
Everyone hates the credit card question, and luckily there is huge variance in answers. At least one site survived Panda despite scoring 5% on this question. Notice that there is a huge overlap between the lowest winner and the average of the losing sites. Also, if you notice by the placement of the mean (blue circle) in the winners category, the average wasn't skewed to the right indicating just one outlier. There was strong variance in the responses across the board. The same was true of the losers. However, with a +15% difference in means, there was a clear average differentiation between the performance of winners and losers. Once again, though, we are drawn back to that aggregate score at the top, where we see how Google can use all these questions together to build a much clearer picture of site and content quality. For example, it is possible that Google pays more attention to this question when it is analyzing a site that has other features like the words "shopping cart" or "check out" on the homepage.
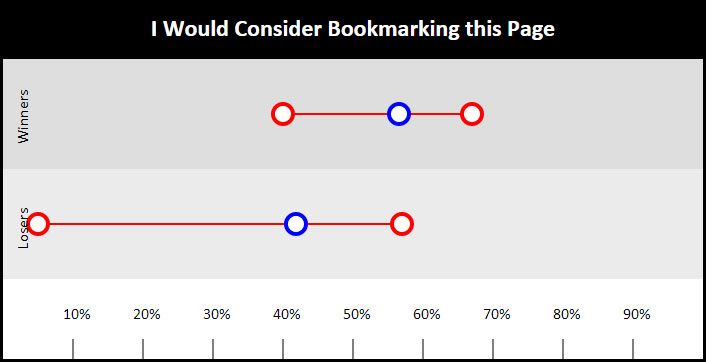
I must admit that the bookmarking question surprised me. I always considered it to be the most subjective of the bunch. It seemed unfair that a site might be judged because it has material that simply doesn't appeal to the masses. The survey just didn't bear this out though. There was a clear difference in means, but after comparing the sites that were from similar content categories, there just wasn't any reason to believe that a bias was created by subject matter. The 14.64% difference seemed to be, editorially speaking, related more to the construction of the page and the quality of the content, not the topic being discussed. Perhaps a better way to think about this question is: would you be embarrassed if your friends knew THIS was the site you were getting your information from rather than another.
This wraps up the 5 questions that had good correlations but substantial enough variance that it was possible for the highest loser to beat out the average winner. I think one clear takeaway from this section is that these questions, while harder to improve upon than the Low Ads and No Errors questions before, are completely within the webmaster's grasp. Making your content and site appear original, trustworthy, authoritative, and worthy of bookmarking aren't terribly difficult. Sure, it takes some time and effort, but these goals, unlike the next, don't appear that far out of reach.
Heavy correlation
The final three questions that seemed to distinguish the most between the winners and losers of Panda 4.1 all had high difference-in-means and, more importantly, had little to no crossover between the highest loser and lowest winner. In my opinion, these questions are also the hardest for the webmaster to address. They require thoughtful design, high quality content, and real, expert human authors.
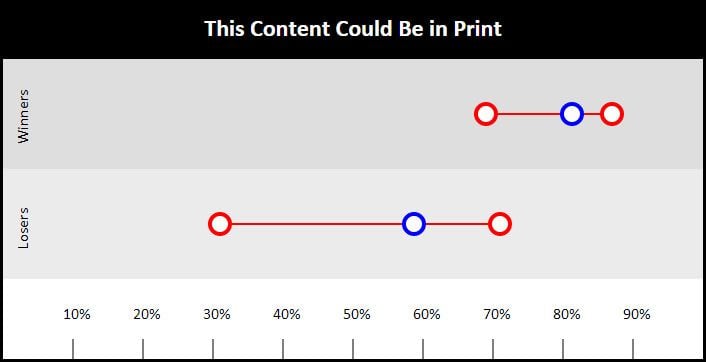
The first question that met this classification was "could this content could appear in print". With a difference in mean of 22.62%, the winners thoroughly trounced the losers in this category. Their sites and content were just better designed and better written. They showed the kind of editorial oversight you would expect in a print publication. The content wasn't trite and unimportant, it was thorough and timely.
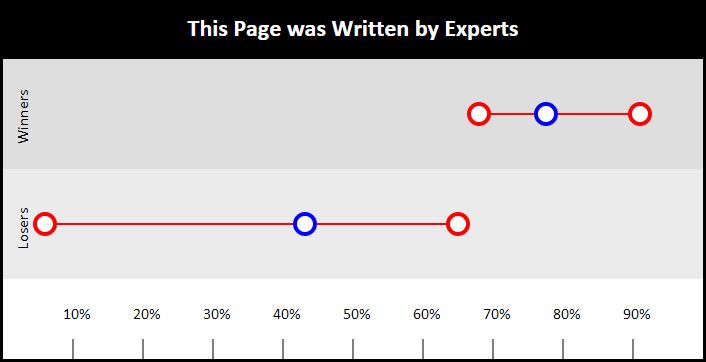
The next heavily correlated question was whether the page was written by experts. With over a 34% difference in means between the winners and losers, and literally no overlap at all between the winners' and losers' individual averages, it was clearly the strongest question. You can see why Google would want to look into things like authorship when they knew that expertise was such a powerful distinguisher between Panda winners and losers. This really begs the question - who is writing your content and do your readers know it?
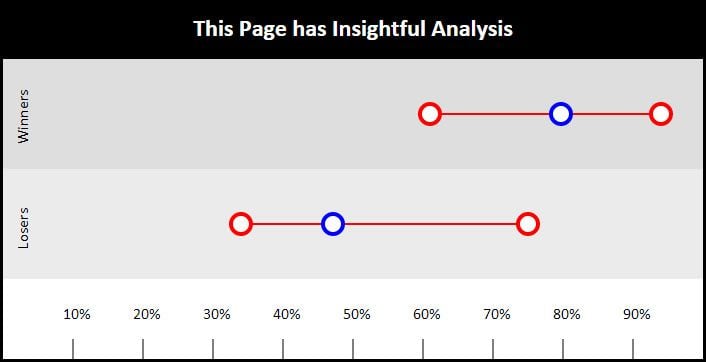
Finally, insightful analysis had a huge difference in means of +32% between winners and losers. It is worth noting that the highest loser is an outlier, which is typified by the skewed mean (blue circle) being closer to the bottom that the top. Most of the answers were closer to the lower score than the top. Thus, the overlap is exaggerated a bit. But once again, this just draws us back to the original conclusion - that the devil is not in the details, the devil is in the aggregate. You might be able to score highly on one or two of the questions, but it won't be enough to carry you through.
The takeaways
OK, so hopefully it is clear that Panda really hasn't changed all that much. The same questions we looked at for Panda 1.0 still matter. In fact, I would argue that Google is just getting better at algorithmically answering those same questions, not changing them. They are still the right way to judge a site in Google's eyes. So how should you respond?
The first and most obvious thing is you should run a Panda survey on your (or your clients') sites. Select a random sample of pages from the site. The easiest way to do this is get an export of all of the pages of your site, perhaps from Open Site Explorer, put them in Excel and shuffle them. Then choose the top 10 that come up. You can follow the Moz instructions I linked to above, do it at PandaRisk, or just survey your employees, friends, colleagues, etc. While the latter probably will be positively biased, it is still better than nothing. Go ahead and get yourself a benchmark.
The next step is to start pushing those scores up one at a time. I give some solid examples on the Panda 4.0 release article about improving press release sites, but there is another better resource that just came out as well. Josh Bachynski released an amazing set of known Panda factors over at his website The Moral Concept. It is well worth a thorough read. There is a lot to take in, but there are tons of easy-to-implement improvements that could help you out quite a bit. Once you have knocked out a few for each of your low-scoring questions, run the exact same survey again and see how you improve. Keep iterating this process until you beat out each of the question averages for winners. At that point, you can rest assured that your site is safe from the Panda by beating the devil in the aggregate.

![How to Optimize for Google's Featured Snippets [Updated for 2024]](https://mza.bundledseo.com/images/blog/banners/599c98d541a541.28015161_2021-03-30-231401.jpg?w=580&h=196&auto=compress%2Cformat&fit=crop&dm=1617146041&s=bcfded4bdc1de1792b6efcfd16b9152f)
Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.