Why are Google SERP Sitelinks "Not Working?"
-
Hi,
I'm hoping someone can provide some insight. I Google searched "citizenpath" recently and found that all of our our sitelinks have identical text. The text seems to come from the site footer. It isn't using the meta descriptions (we definitely have) or even a Google-dictated snippet from the page. I understand we don't have "control" of this. It's also worth mentioning that if you search a specific page like "contact us citizenpath" you'll get a more appropriate excerpt.
Can you help us understand what is happening? This isn't helpful for Google users or CitizenPath. Did the Google algorithm go awry or is there a technical error on our site? We use up-to-date versions of Wordpress and Yoast SEO. Thanks!
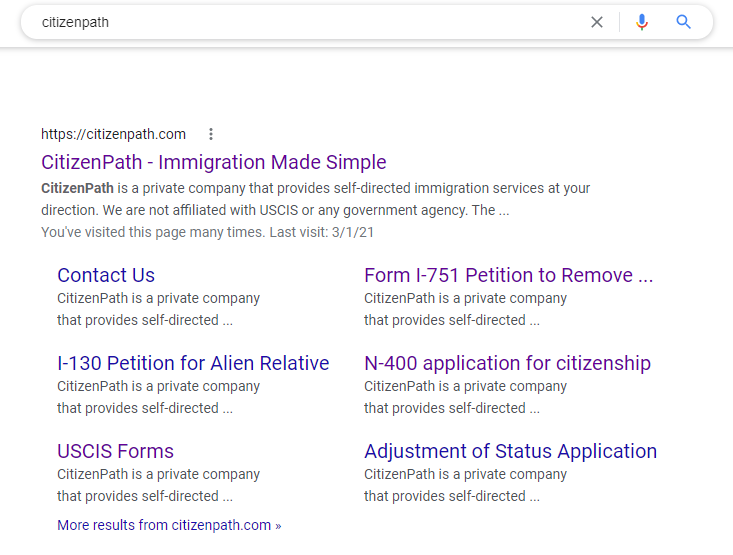
-
@123russ let me know how it goes.
PS: I'd appreciate upvote if you find my suggestions helpful. -
@123russ let me know how it goes.
PS: I'd appreciate upvote if you find my suggestions helpful. -
@terentyev Thank you for taking the time to review this. I'll ask our team to review your suggestions.
-
@123russ I checked your site, and it seems that there is an issue with embedded iframes you are using on your site.
Check out your document outline in W3 validator and tell your developer to fix fatal errors (in your case - multiple body tags).Another thing I would do is to add the texts that you are using in meta descriptions somewhere on the top of the page, behind the H1 title.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

"non-WWW" vs "WWW" in Google SERPS and Lost Back Link Connection
A Screaming Frog report indicates that Google is indexing a client's site for both: www and non-www URLs. To me this means that Google is seeing both URLs as different even though the page content is identical. The client has not set up a preferred URL in GWMTs. Google says to do a 301 redirect from the non-preferred domain to the preferred version but I believe there is a way to do this in HTTP Access and an easier solution than canonical.
Technical SEO | | RosemaryB
https://support.google.com/webmasters/answer/44231?hl=en GWMTs also shows that over the past few months this client has lost more than half of their backlinks. (But there are no penalties and the client swears they haven't done anything to be blacklisted in this regard. I'm curious as to whether Google figured out that the entire site was in their index under both "www" and "non-www" and therefore discounted half of the links. Has anyone seen evidence of Google discounting links (both external and internal) due to duplicate content? Thanks for your feedback. Rosemary0 -

Why is Google replacing our title tags with URLs in SERP?
Hey guys, We've noticed that Google is replacing a lot of our title tags with URLs in SERP. As far as we know, this has been happening for the last month or so and we can't seem to figure out why. I've attached a screenshot for your reference. What we know: depending on the search query, the title tag may or may not be replaced. this doesn't seem to have any connection to the relevance of the title tag vs the url. results are persistent on desktop and mobile. the length of the title tag doesn't seem to correlate with the replacement. the replacement is happening at mass, to dozens of pages. Any ideas as to why this may be happening? Thanks in advance,
Technical SEO | | Mobify
Peter mobify-site-www.mobify.com---Google-Search.png0 -

New "Static" Site with 302s
Hey all, Came across a bit of an interesting challenge recently, one that I was hoping some of you might have had experience with! We're currently in the process of a website rebuild, for which I'm really excited. The new site is using Markdown to create an entirely static site. Load-times are fantastic, and the code is clean. Life is good, apart from the 302s. One of the weird quirks I've realized is that with oldschool, non-server-generated page content is that every page of the site is an Index.html file in a directory. The resulting in a www.website.com/page-title will 302 to www.website.com/page-title/. My solution off the bat has been to just be super diligent and try to stay on top of the link profile and send lots of helpful emails to the staff reminding them about how to build links, but I know that even the best laid plans often fail. Has anyone had a similar challenge with a static site and found a way to overcome it?
Technical SEO | | danny.wood1 -

"Fourth-level" subdomains. Any negative impact compared with regular "third-level" subdomains?
Hey moz New client has a site that uses: subdomains ("third-level" stuff like location.business.com) and; "fourth-level" subdomains (location.parent.business.com) Are these fourth-level addresses at risk of being treated differently than the other subdomains? Screaming Frog, for example, doesn't return these fourth-level addresses when doing a crawl for business.com except in the External tab. But maybe I'm just configuring the crawls incorrectly. These addresses rank, but I'm worried that we're losing some link juice along the way. Any thoughts would be appreciated!
Technical SEO | | jamesm5i0 -

Campaign Issue: Rel Canonical - Does this mean it should be "on" or "off?"
Hello, somewhat new to the finer details of SEO - I know what canonical tags are, but I am confused by how SEOmoz identifies the issue in campaigns. I run a site on a wordpress foundation, and I have turned on the option for "canonical URLs" in the All in one SEO plugin. I did this because in all cases, our content is original and not duplicated from elsewhere. SEOmoz has identified every one of my pages with this issue, but the explanation of the status simply states that canonical tags "indicate to search engines which URL should be seen as the original." So, it seems to me that if I turn this OFF on my site, I turn off the notice from SEOmoz, but do not have canonical tags on my site. Which way should I be doing this? THANK YOU.
Technical SEO | | mrbradleyferguson0 -

Can name="author" register as a link?
Hi all, We're seeing a very strange result in Google Webmaster tools. In "Links to your site", there is a site which we had nothing to do with (i.e. we didn't design or build it) showing over 1600 links to our site! I've checked the site several times now, and the only reference to us is in the rel="author" tag. Clearly the agency that did their design / SEO have nicked our meta, forgetting to delete or change the author tag!! There are literally no other references to us on this site, there hasn't every been (to our knowledge, at least) and so I'm very puzzled as to why Google thinks there are 1600+ links pointing to us. The only thing I can think of is that Google will recognise name="author" content as a link... seems strange, though. Plus the content="" only contains our company name, not our URL. Can anybody shed any light on this for me? Thanks guys!
Technical SEO | | RiceMedia0 -

Sitemaps for Google
In Google Webmaster Central, if a URL is reported in your site map as 404 (Not found), I'm assuming Google will automatically clean it up and that the next time we generate a sitemap, it won't include the 404 URL. Is this true? Do we need to comb through our sitemap files and remove the 404 pages Google finds, our will it "automagically" be cleaned up by Google's next crawl of our site?
Technical SEO | | Prospector-Plastics0 -

Google penalty
Anyone have any success stories on what they did to get out of Google penalty?
Technical SEO | | phatride0