Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
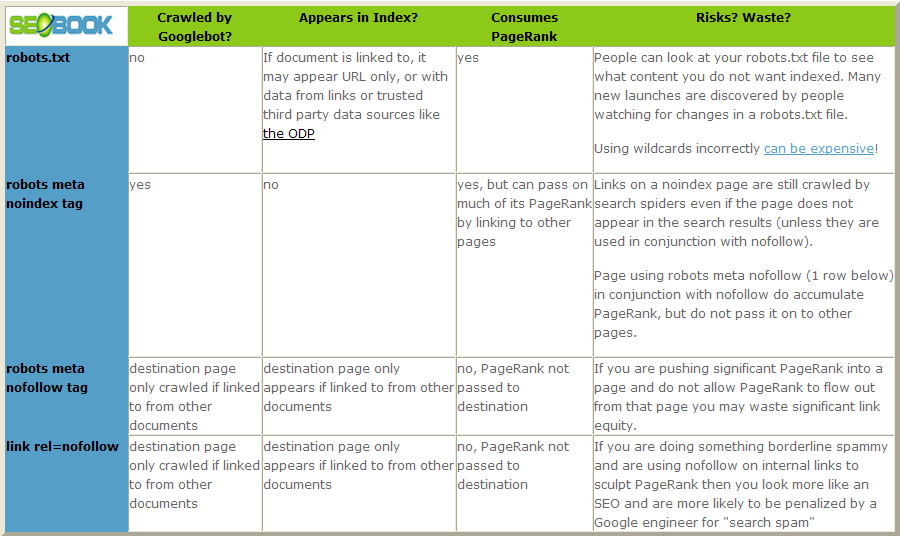
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

What are the things that need update? before Appying SEO
Hello Everyone, I need Start work on for this site www.tajsigma.com, I want to know Did i need Add any things for Good ranking. what are the things that need update in This site For SEO??
Technical SEO | | falguniinnovative
i know Basic Things robots, title, discription , But i want know Any Additional Things that I need to apply?? can anyone help, please Thanx in advance0 -

Rel-canonical and meta data
Hey Mozzers, Help please. I am migrating content for a new website (1000's of pages) and am using the canonical tag on a number of pages. For the pages which I am asking Google not to recognise / index as the master version, and in the interests of time do I need to take the time to fill in the meta <title><description> etc each time?</p> <p>Ben</p></title>
Technical SEO | | Bendall0 -

Robots.txt on refinements
In dealing with Panda do you think it is a good idea to put all refinements for category pages in the robots.txt file? We already have a lot as noindex, follow but I am wondering if it would be better to address from a crawl perspective as the pages are probably thin duplicate content to Google.
Technical SEO | | Gordian0 -

Easy Question: regarding no index meta tag vs robot.txt
This seems like a dumb question, but I'm not sure what the answer is. I have an ecommerce client who has a couple of subdirectories "gallery" and "blog". Neither directory gets a lot of traffic or really turns into much conversions, so I want to remove the pages so they don't drain my page rank from more important pages. Does this sound like a good idea? I was thinking of either disallowing the folders via robot.txt file or add a "no index" tag or 301redirect or delete them. Can you help me determine which is best. **DEINDEX: **As I understand it, the no index meta tag is going to allow the robots to still crawl the pages, but they won't be indexed. The supposed good news is that it still allows link juice to be passed through. This seems like a bad thing to me because I don't want to waste my link juice passing to these pages. The idea is to keep my page rank from being dilluted on these pages. Kind of similar question, if page rank is finite, does google still treat these pages as part of the site even if it's not indexing them? If I do deindex these pages, I think there are quite a few internal links to these pages. Even those these pages are deindexed, they still exist, so it's not as if the site would return a 404 right? ROBOTS.TXT As I understand it, this will keep the robots from crawling the page, so it won't be indexed and the link juice won't pass. I don't want to waste page rank which links to these pages, so is this a bad option? **301 redirect: **What if I just 301 redirect all these pages back to the homepage? Is this an easy answer? Part of the problem with this solution is that I'm not sure if it's permanent, but even more importantly is that currently 80% of the site is made up of blog and gallery pages and I think it would be strange to have the vast majority of the site 301 redirecting to the home page. What do you think? DELETE PAGES: Maybe I could just delete all the pages. This will keep the pages from taking link juice and will deindex, but I think there's quite a few internal links to these pages. How would you find all the internal links that point to these pages. There's hundreds of them.
Technical SEO | | Santaur0 -

Meta Description VS Rich Snippets
Hello everyone, I have one question: there is a way to tell Google to take the meta description for the search results instead of the rich snippets? I already read some posts here in moz, but no answer was found. In the post was said that if you have keywords in the meta google may take this information instead, but it's not like this as i have keywords in the meta tags. The fact is that, in this way, the descriptions are not compelling at all, as they were intended to be. If it's not worth for ranking, so why google does not allow at least to have it's own website descriptions in their search results? I undestand that spam issues may be an answer, but in this way it penalizes also not spammy websites that may convert more if with a much more compelling description than the snippets. What do you think? and there is any way to fix this problem? Thanks!
Technical SEO | | socialengaged
Eugenio0 -

SEO Yoast Help Needed
Anyone familar with SEO Yoast and interested in being hired to check out my settings for SEO. Thinking about 30 minute screen sharing session an helping me figure out what I am am doing wrong? Just cleaned up duplicates because of tags and now I see the images are getting duplicated as well as some of the titles. So new to Wordpress here I shine. Message me if you can help. Much Appreciated!!
Technical SEO | | Force70 -

Robots.txt Sitemap with Relative Path
Hi Everyone, In robots.txt, can the sitemap be indicated with a relative path? I'm trying to roll out a robots file to ~200 websites, and they all have the same relative path for a sitemap but each is hosted on its own domain. Basically I'm trying to avoid needing to create 200 different robots.txt files just to change the domain. If I do need to do that, though, is there an easier way than just trudging through it?
Technical SEO | | MRCSearch0 -

Need Help With Robots.txt on Magento eCommerce Site
Hello, I am having difficulty getting my robots.txt file to be configured properly. I am getting error emails from Google products stating they can't view our products because they are being blocked, and this past week, in my SEO dashboard, the URL's receiving search traffic dropped by almost 40%. Is there anyone that can offer assistance on a good template robots.txt file I can use for a Magento eCommerce website? The one I am currently using was found at this site here: e-commercewebdesign.co.uk/blog/magento-seo/magento-robots-txt-seo.php - However, I am getting problems from Google now because of it. I searched and found this thread here: http://www.magentocommerce.com/wiki/multi-store_set_up/multiple_website_setup_with_different_document_roots#the_root_folder_robots.txt_file - But I felt like maybe I should get some additional help on properly configuring a robots for a Magento site. Thanks in advance for any help. Please, let me know if you need more info to provide assistance.
Technical SEO | | JerDoggMckoy0