Why do I have one page showing as two url's?
-
My SEOMoz stats show that I have duplicate titles for the following two url's:
http://www.rmtracking.com/products.php and http://www.rmtracking.com/products
I have checked my server files, and I don't see a live page without the php. A while back, we converted our site from html to php, but the html pages have 301's and as you can see the page without the php is properly redirecting to the php page. Any ideas why this would show as two separate url's?
-
I think you were right. I did what you said and found it linked from a flash file. Since this is the only one showing in the csv crawl report, I think it's fixed. Thanks very much for your help!
Brad
-
I am inclined to think you must be linking to it somewhere if it is showing up in a crawl. Export your crawl to a csv and search for it and check the referring page.
-
First link is your standard .php page
Second link is a duplicate of page 1 http://www.rmtracking.com/products/index.php
In other words it sees http://www.rmtracking.com/products/index.php as http://www.rmtracking.com/products/ which is a duplicate
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

URL Structure On Site - Currently it's domain/product-name NOT domain/category/product name is this bad?
I have a eCommerce site and the site structure is domain/product-name rather than domain/product-category/product-name Do you think this will have a negative impact SEO Wise? I have seen that some of my individual product pages do get better rankings than my categories.
Technical SEO | | the-gate-films0 -

Webmaster tools not showing links but Moz OSE is showing links. Why can't I see them in the Google Search Console
Hi, Please see attached photos. I have a website that shows external follow links when performing a search on open site explorer. However, they are not recognised or visible in search console. This is the case for both internal and external links. The internal links are 'no follow' which I am getting developer to rectify. Any ideas why I cant see the 'follow' external links? Thanks in advance to those who help me out. Jesse T7dkL5s T7dkL5s OkQmPL4 3qILHqS
Technical SEO | | jessew0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
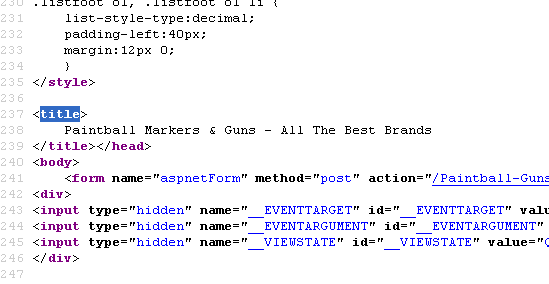 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Switchboard Tags - Multiple desktop pages pointing to one mobile page
I have recently started to implement switchboard tags to connect our mobile and desktop pages, and to ensure that our mobile pages show up in rankings for mobile users. Because our desktop site is much deeper in content than our mobile site, there are a number of desktop pages we would like to have point to one mobile page. However, with the switchboard tags, this poses a problem because it requires multiple rel=canonical tags to be placed on the one mobile page. I'm assuming this will either confuse the search engines, or they will choose to ignore the rel=canonical tag altogether. Any ideas on how to approach this situation other than creating an equivalent mobile version of every desktop page or implementing a user agent detection redirect?
Technical SEO | | JBlank0 -

Hashtag in url seems to remove the google plus one
My site has a catalogue page (catalog in US) with #anchors so that customers can get straight to them. I even link from other pages to the #anchor on the catalogue page. so I have for example: www.example.co.uk/catalogue.htm www.example.co.uk/catalogue.htm#blueitems www.example.co.uk/catalogue.htm#redtems I understand google doesn't index after the #, here is the post I found: http://moz.com/community/q/hashtag-anchor-text-within-content#reply_91192 So I shouldn't have an seo problem. BUT, if I navigate to www.example.co.uk/catalogue.htm and plusone the page it will show the plusone and then I navigate to www.example.co.uk/catalogue.htm#blueitems the plus one is gone. The same happens in reverse, if i plusone www.example.co.uk/catalogue.htm#redtems, then that plusone doesn't show in www.example.co.uk/catalogue.htm. I added rel=canonical and that fixed the plusone problem, now if you plus one /catalogue.htm#redtems it still shows on catalogue.htm This seems a bit extreme and did I do the right things??
Technical SEO | | Peter24680 -
Should I change by URL's
I started with a static website and then moved to Wordpress. At the time I had a few hundred pages and wanted to keep the same URL structure so I use a plugin that adds .html to every page. Should I change the structure to a more common URL structure and do 301 directs from the .html page to the regular page?
Technical SEO | | JillB20130 -

Moz Reporting Incorrect 404's
Hi Guys SEOMoz is telling me that we have 191 404 errors f. I have checked this with several other crawlers and this not the case. For example, http://www.opticalexpress.co.uk/eyecare/corporate-savings.html%0D%0A2027 But correct links its http://www.opticalexpress.co.uk/eyecare/corporate-savings.html which is fine... We have no record of these links so why is it appending these characters at the end of the URL which is causing the 404's....
Technical SEO | | EwanFisher0 -
Removing a site from Google's index
We have a site we'd like to have pulled from Google's index. Back in late June, we disallowed robot access to the site through the robots.txt file and added a robots meta tag with "no index,no follow" commands. The expectation was that Google would eventually crawl the site and remove it from the index in response to those tags. The problem is that Google hasn't come back to crawl the site since late May. Is there a way to speed up this process and communicate to Google that we want the entire site out of the index, or do we just have to wait until it's eventually crawled again?
Technical SEO | | issuebasedmedia0