Strange Crawl Report
-
Hey Moz Squad,
So I have kind of strange case. My website locksmithplusinc.com has been around for a couple years. I have had all sorts of pages and blogs that have maybe ranked for a certain location a longtime ago and got deleted so I could speed up the site and consolidate my efforts. I said that because I think that might be part of the problem.
When I was crawl reporting my site just three weeks ago on moz I had over 23 crawl report issues. Duplicate pages, missing meta tags the regular stuff. But now all of a sudden when I crawl report on MOZ it comes up with Zero issues. So I did another crawl On google analytic and this is what came up.
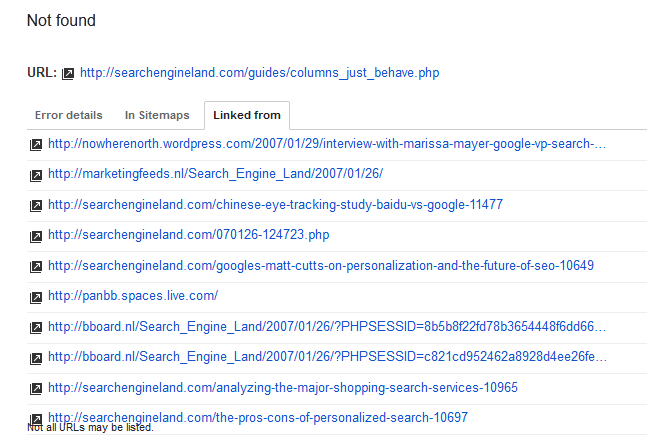
SO im very confused because none of these url's are even url's on my site. So maybe people are searching for this stuff and clicking on broken links that are still indexed and getting this 404 error?
What do you guys think?
Thank you guys so much for taking a shot at this one.
-
The team from Giovatto is correct, you can click on the url and see where it is being linked from.
-
These are "Not Found" errors, meaning they are pages that do not exist but are being linked to somewhere on your site or another site.
If the page that is not found is a relevant page that holds a prominent ranking position, then by all means you probably want to either fix the broken link that was found or 301 redirect this broken URL to the correct URL.
You can check what page is linking to this broken URL by clicking the URL in the error report and switching to the "Linked From" tab and then decide if it's something that needs to be fixed.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Tools/Software that can crawl all image URLs in a site
Excluding Screaming Frog, what other tools/software to use in order to crawl all image URLs in a site? Because in Screaming Frog, they don't crawl image URLs which are not under the site domain. Example of an image URL outside the client site: http://cdn.shopify.com/images/this-is-just-a-sample.png If the client is: http://www.example.com, Screaming Frog only crawls images under it like, http://www.example.com/images/this-is-just-a-sample.png
Technical SEO | | jayoliverwright0 -

My site was hacked and spammy URLs were injected that pointed out. The issue was fixed, but GWT is still reporting more of these links.
Excuse me for posting this here, I wasn't having much luck going through GWT support. We recently moved our eCommerce site to a new server and in the process the site was hacked. Spammy URLs were injected in, all of which were pointing outwards to some spammy eCommerce retail stores. I removed ~4,000 of these links, but more continue to pile in. As you can see, there are now over 20,000 of these links. Note that our server support team does not see these links anywhere. I understand that Google doesn't generally view this as a problem. But is that true given my circumstance? I cannot imagine that 20,000 new, senseless 404's can be healthy for my website. If I can't get a good response here, would anyone know of a direct Google support email or number I can use for this issue?
Technical SEO | | jampaper0 -

Google not crawling the website from 22nd October
Hi, This is Suresh. I made changes to my website and I see that google is unable to crawl my website from 22nd October. Even it is not showing any content when I use Cache:www.vonexpy.com. Can any body help me in knowing why Google is unable to crawl my website. Is there any technical issue with the website? Website is www.vonexpy.com Thanks in advance.
Technical SEO | | sureshchowdary1 -

Site was infected with spam webmaster tools still reporting it
I have recently been working with a site that was hacked. It suffered from a pharma injection into Joomla. The site has been cleaned for several months, but WMT is still reporting "pharmacy" as occuring 421 times. The url it gives reports a 500 error. I also removed it in Google. Can this still be hurting the site? How can I clean this up?
Technical SEO | | smcmark0 -

Bug in Competitor Rankings Report?
I am looking at the report called: Rankings Report for [Competitor XXX] For all keywords in the report, the rankings on the main page say "Not in Top 50"... however when I drill down I can see that this is not true... there is a graph with valid rankings which were gathered as recently as March 20, 2013 (2 days ago) is this a known bug? Regards Jim Donovan
Technical SEO | | wethink0 -

How does Google Crawl Multi-Regional Sites?
I've been reading up on this on Webmaster Tools but just wanted to see if anyone could explain it a bit better. I have a website which is going live soon which is going to be set up to redirect to a localised URL based on the IP address i.e. NZ IP ranges will go to .co.nz, Aus IP addresses would go to .com.au and then USA or other non-specified IP addresses will go to the .com address. There is a single CMS installation for the website. Does this impact the way in which Google is able to search the site? Will all domains be crawled or just one? Any help would be great - thanks!
Technical SEO | | lemonz0 -

Blocking AJAX Content from being crawled
Our website has some pages with content shared from a third party provider and we use AJAX as our implementation. We dont want Google to crawl the third party's content but we do want them to crawl and index the rest of the web page. However, In light of Google's recent announcement about more effectively indexing google, I have some concern that we are at risk for that content to be indexed. I have thought about x-robots but have concern about implementing it on the pages because of a potential risk in Google not indexing the whole page. These pages get significant traffic for the website, and I cant risk. Thanks, Phil
Technical SEO | | AU-SEO0 -

Should we use Google's crawl delay setting?
We’ve been noticing a huge uptick in Google’s spidering lately, and along with it a notable worsening of render times. Yesterday, for example, Google spidered our site at a rate of 30:1 (google spider vs. organic traffic.) So in other words, for every organic page request, Google hits the site 30 times. Our render times have lengthened to an avg. of 2 seconds (and up to 2.5 seconds). Before this renewed interest Google has taken in us we were seeing closer to one second average render times, and often half of that. A year ago, the ratio of Spider to Organic was between 6:1 and 10:1. Is requesting a crawl-delay from Googlebot a viable option? Our goal would be only to reduce Googlebot traffic, and hopefully improve render times and organic traffic. Thanks, Trisha
Technical SEO | | lzhao0