Is this correct?
-
I noticed Moz using the following for its homepage
Is this best practice though? The reason I ask is that, I use and I've been reading this page by Google
http://googlewebmastercentral.blogspot.co.uk/2013/04/5-common-mistakes-with-relcanonical.html
5 common mistakes with rel=canonical
Mistake 2: Absolute URLs mistakenly written as relative URLs
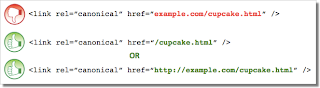
The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
-
Thanks
-
Ow im sorry, totally mis understood - sorry if i was explaining something you understood.
Moz use
you said they use
/> i presume now you mean the / at the end of the tag.
This is an old school closing tag. HTML elements were traditionally opened and closed in HTML versions before HTML5. Normally this is done obviously with tags such the opener "
" and closer "
". However some elements dont have a seperate closing tag such as "" tags. In older html versions these were closed using the format
Missing these tags didn't used to do much as most browsers rendered the page correctly anyways, but best practice was to include the / to close elements. However with the dawn of HTML5 things changed.
HTML5 doesn't require the closing tag. Elements that used to require one now simply dont. Browsers still understand both versions absolutely fine and its kinda ok to use either. But the most modern and correct practice is to use it without.
Edit:
Racking my brain, i believe the / was added as best practice to assure compatibility with XHTML which was pegged to be the next version of HTML. When XHTML was scrapped in favour of HTML5 it changed. Somebody may correct me on this one though
")
-
Thanks, I realise the usage should be a correct relative URL or a correctly formed absolute URL. In Moz's case, they used a correctly formed absolute URL.
My question is more around...why not use "/"?
Cyto
-
Looks fine to me, i think you misunderstand Mistake 2
They are using an absolute URL
If they did the "mistake 2" their canonical tag would look like
You canonical tags should always be absolute for good practice
is correct
or any variant of this would be wrong

Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

H1 and Schema Codes Set Up Correctly?
Greetings: It was pointed out to me that the h1 tags on my website (www.nyc-officespace-leader.com) all had exactly the same text and that duplication may be contributing to the very low page authority for most URLs. The duplicate h1 appears in line 54-54 (see below) of the home page: www.nyc-officespace-leader.com: itemscope itemtype="http://schema.org/LocalBusiness" style="position:absolute;top:-9999em;"> <span<br>itemprop="name">Metro Manhattan Office Space</span<br> <img< p="">But the above refers to schema" so is this really duplicate H1 or is there an exception if the H1 is within a schema? Also, I was told that the company street address and city and state were set up incorrectly as part of an alt tag. However these items also appear as schema in lines 49-68 shown below: Dangerous for me to perform surgery on the code without being certain about these key items!! Could ask my developer, however they may be uncomfortable considering that they set this up in the 1st place. So the view of neutral professionals would be highly welcome! itemprop="address" itemscope itemtype="http://schema.org/PostalAddress">
Intermediate & Advanced SEO | | Kingalan1
<span<br>itemprop="streetAddress">347 5th Ave #1008
<span<br>itemprop="addressLocality">New York
<span<br>itemprop="addressRegion">NY
<span<br>itemprop="postalCode">10016<div<br>itemprop="brand" itemscope itemtype="http://schema.org/Organization">
---------------------------------------------------------------------------</div<br></span<br></span<br></span<br></span<br></img<>0 -

Canonical code set up correctly?
Please let me know if this makes sense. I have a very limited knowledge of technical SEO but I am almost positive that my web developer did something wrong. I have a wordpress blog and he did add canonical code to some of the pages. However he directs the site to the same URL! Does this mean that the canonical code is setup incorrectly and actually harming my SEO performance. Also if I have one webpage with just the first paragraph of a blog post I wrote and a completely seperate page for the blog post itself, could this be considered duplicate content? Thanks!!
Intermediate & Advanced SEO | | DR700950 -

Correct strategy for long-tail keywords?
Hi, We are selling log houses on our website. Every log house is listed as a "product", and this "product" consists of many separate parts, that are technically also products. For example a log house product consists of doors, windows, roof - and all these parts are technically also products, having their own content pages. The question is - Should we let google index these detail pages, or should we list them as noindex? These pages have no content, only the headline, which are great for long-tail SEO. We are probably the only manufacturer in the world who has a separate page for "log house wood beam 400x400mm". But otherwise these pages are empty. My question is - what should we do? Should we let google index them all (we have over 3600 of them) and maybe try to insert an automatic FAQ section to every one of them to put more content on the page? Or will 3600 low-content pages hurt our rankings? Otherwise we are ranking quite well. Thanks, Johan
Intermediate & Advanced SEO | | JohanMattisson0 -

Site Explorer, Social Media Count. Am I linking my social media correctly?
How do I correctly link my social media pages? I have link going from my Twitter, Facebook and Google + to my website. But a quick Open site explorer check says that I have, 0 Facebook Friends, 0 Twitter followers and 0 Google + Followers. Where as in relaity, I have 100 - 1000 follwers on each. Infact, the hyperlink from my Twitter Profile section doesn't appear as a no follow link atall on an OSE check of my website. Am I linking social media wrong?
Intermediate & Advanced SEO | | Paul_Tovey0 -

Title tags not displaying correctly?
If I have a title tag with 28 words (around 90 letters) with some repetition and Google has decided not to use this in the SERPS is this a bad thing (basically saying the title tag is not liked by Google).
Intermediate & Advanced SEO | | BobAnderson0 -

Correcting an unnatural link profile
A site I work with ranked page 1 for a competitive keyphrase until recently. (Not Panda-related as far as we can tell.) We've done extensive on-site tweaking and the page is still parked at 27-32 in the SERPs. We believe the only viable explanation at this point is an unnatural link profile. Over the course of several years the site has racked up a large collection of footer links with anchor text due to business relationships with the sites in question. So the profile is now skewed, with the result as follows: 100,000 domain links (top 10 competitors range 1800-50k) 87% anchor text optimized (competitors 0-41%) 99% follow links (competitors 85-100%) The vast majority of links are footer links We're working on creating more natural, high-value links but this of course takes time. In the short term, two questions: Should we aim to remove or change some of the footer links? If so, do we remove them, or just change anchor text? How many? How many new links should we pursue each month to make a meaningful impact on the profile without being too aggressive? Any other thoughts on how to fix this are also appreciated. Thanks!
Intermediate & Advanced SEO | | kdcomms0 -

Any ideas for capturing keywords that your client rejects because they aren't politically correct?
Here's the scenario: you need to capture a search phrase that is very widely used in common search, but the term is considered antiquated, overly vernacular, insensitive or outright offensive within the client's industry. In this case, searchers overwhelmingly look for "nursing homes," but the term has too many negative connotations to the client's customers, so they won't use it on-page. Some obvious thoughts are to build IBLs or write an op-ed/blog series about why the term is offensive. Any other ideas?
Intermediate & Advanced SEO | | Jeremy_FP1