Crawling Problem : No-data Of My Site
-
Hey, Folks!!
So It's Been More than a Month.And Moz is not crawling my website http://www.trickypedia.com/.I have seen Moz Last update I thought they will crawl my site but No results Disappointing. My Sites Domain Authority and Page Authority is still 1. But In other Seo Tools, they are Perfectly Crawling My Website. What Would Be the reason? Can anyone Please Explain.
-
If your website is experiencing a "no-data" issue during crawling by search engines, several factors may be at play. Check your robots.txt file, ensure proper HTTP status codes, examine your meta tags, confirm content accessibility, and investigate for technical errors. cloaking facebook ads consider the quality of your content, the efficiency of your crawl budget, mobile compatibility, and overall site security. Additionally, use webmaster tools for insights and, if needed, consult web development or SEO professionals for a comprehensive audit and solutions.
-
If your website is experiencing a "no-data" issue during crawling by search engines, several factors may be at play. Check your
robots.txtfile, ensure proper HTTP status codes, examine your meta tags, confirm content accessibility, and investigate for technical errors. Consider the quality of your content, the efficiency of your crawl budget, mobile compatibility, and overall site security. Additionally, use webmaster tools for insights and, if needed, consult web development or SEO professionals for a comprehensive audit and solutions. -
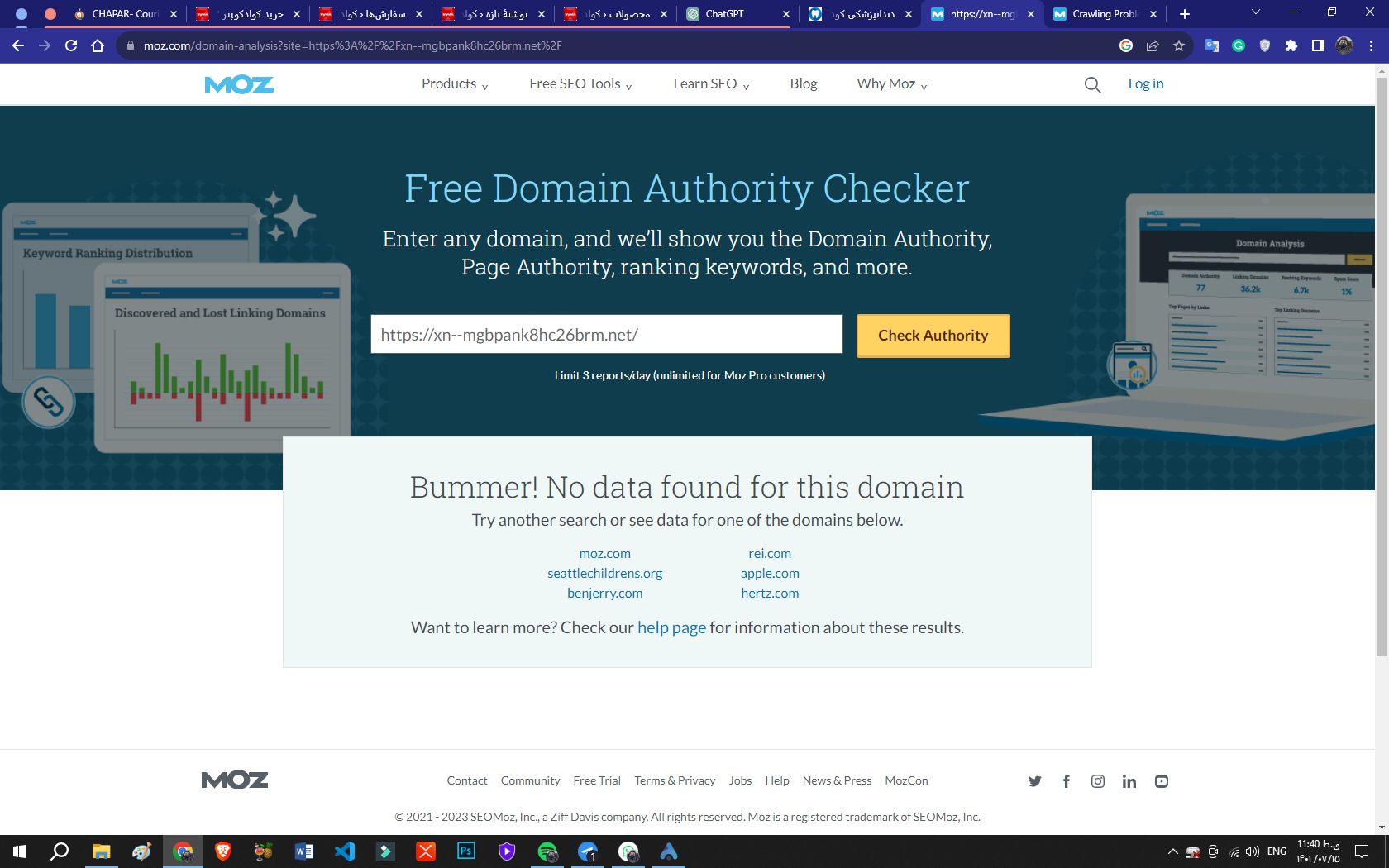
<h2>why my site not get verified from moz??</h2>
I created a website and I have ranked 1 in most of my keywords. and my site's traffic is normal and I have a fine domain authority but Moz still doesn't show any data on my website
could you guys check it and fix that problem for me??
my website (https://دندانپزشک.net/)
this is the address of my website
thank you<3
-
-
Hi there!
It sounds like you're wondering why we haven't got link data for you in OSE. There are a few possible reasons why your site might not be indexed.
The first thing to check is if your site uses a custom Top Level Domain (TLD), like .agency or .london. If so, then you won't see data for your site in our index, as we don't currently support custom TLDs. Unfortunately there isn't a good workaround for this—it's a technical limitation of the tool. I can see you site http://www.trickypedia.com/ doesn't use a custom TLD, so you're good.
If your site isn't linked to by one of the seed URLs used to build our index, then our bot won't be able to find it and add it to our map. Learn more about how we index the web.
In addition to this, Mozscape focuses on a breadth-first approach. Therefore we almost always have content from the homepage of websites, externally linked-to pages, and pages higher up in a site's information hierarchy. However, deep pages that are buried beneath many layers of navigation are sometimes missed, and it may be several index updates before we catch all of these.
If our crawlers or data sources are blocked from reaching those URLs, they may not be included in our index (though links that point to those pages will still be available).
Finally, the URLs seen by Mozscape must be linked-to by other documents on the web or our index will not include them.
If links to your pages have not been indexed and you have links from high Authority pages, you might want to check to see if we have indexed the pages linking to your site. Enter the URL that you know if linking you into Open Site Explorer and see if we've got those in our index. You'll also want to make sure that we aren't blocked from crawling the site. If our web crawlers are blocked from crawling certain pages (i.e., with "noindex" or a Robots.txt exclusion), they may not be included in the index.
I hope this helps, please do let me know if you would like more clarification or have any other queries.
Jo
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Download of current keyword rankings WITHOUT historical data
Hi there, I would like to download the current keyword rankings within a campaign without the historical data i.e. I need only ONE row for each keyword. I read an earlier post that suggested setting the data parameters within the last update period but I can't do this on my MOZ interface - whatever I set the dates to, I still get multiple rows for each keyword. I guess there must be a way to do what I need but I can't see it! Please advise. Many thanks
Moz Bar | | colinking1 -

Crawl report shows that it gets 4xx errors for pages that work fine. Why?
On the crawl report it has all these "Critical Crawler Issues". They all say "4xx Error", yet when i click on the link from the crawler report, it goes to a perfectly functioning page, not a 404 page or anything. If i click in it actually says it's a 403 error. It's all for pages generated by the IDX solution for our real estate website. Is Moz broken or am i missing something? Here are a couple examples: <dl class="crawl-page-details-list"> <dd class="crawl-page-details-list-emphasis">https://teamvivi.com/homes-for-sale-map-search/</dd> <dd class="crawl-page-details-list-emphasis"> <dl class="crawl-page-details-list"> <dd class="crawl-page-details-list-emphasis">https://teamvivi.com/email-alerts/</dd> </dl> </dd> </dl>
Moz Bar | | TeamViviRealEstate0 -

Possible bug in Crawl Issues report?
Hi all - My crawl issues report shows 3 pages with missing titles. These are just google verification files and the robot.txt file - shouldn't these be excluded? Pages with Title Missing or Emptyas of May 11
Moz Bar | | A-Drive
URL Page Authority Linking Root Domains
https://www.mysite.com/googlea87e28121c071983.html
1 0
https://www.mysite.com/robots.txt
1 0
https://www.mysite.com/google9b9dc57478f61677.html0 -

Can we export Historical Campaign Data
I want to know if there is a way to export data from my campaigns from more than a month ago. My campaigns started in August. I would like to be able to export a PDF of my dashboard for Aug and September. I have Oct and Nov. Any idea if this is possible?
Moz Bar | | MonicaOConnor0 -

Does anyone have a good article or video on how to read the SEO MOZ crawl report column by column?
I am trying to find a good how-to on how to read and analyze each column of the SEO MOZ crawl report, specifically, the excel sheet it allows you to export. What I'm really trying to get to the bottom of is what the "Yes" indiciates under rel-cononical. If it says "yes," does this mean that the link in question has been canonoicalized?
Moz Bar | | armcwill0 -

408 errors in crawl diagnostics
Best community, The Crawl Diagnostics Report of Moz gave our website a lot of 408 errors like below: <dl> <dt>Title</dt> <dd>408 : Error</dd> <dt>Meta Description</dt> <dd>408 Request Time-out</dd> <dt>Meta Robots</dt> <dd>Not present/empty</dd> <dt>Meta Refresh</dt> <dd>Not present/empty</dd> <dd>-----------------------------------------------------------------------</dd> <dd>The report has diagnosed a lot of these (around 320), even though we cannot reproduce the error (we cannot seem to find it ourself). </dd> <dd>2 questions relating to this: </dd> <dd>* Can you (the people of Moz) reproduce the errors manually? </dd> <dd>* Is it possible that it is a bug in the spider of Moz itself (too many spiders crawling at the same time)?</dd> </dl>
Moz Bar | | arjen.koedam0 -

Is Manual Crawl Test option available now to Pro Users?
Hi all, I have worked on my Crawl Issues and want to see how many still exist. Earlier I was using Manual Crawl Test. However, now I don't see this tool in Moz Account. Please suggest. Thanks
Moz Bar | | chandman0 -

Blocked Production Site from Search Engines - How to get it Crawled by Moz Crawler
I have an 'under development' site hosted, (which is an exact replica of live site as working on to add new functionalities & modules) - but its password protected, excluded from robots.txt (Disallow) & also marked noindex on all pages in the index - so that Googlebot & other Search Engines can not crawl the site At present the development work is almost 95% completed., Now - feel like to crawl the site through SEOMOZ Roger Bot - to know the errors and all indexed urls by Rogerbot. What's the best way to get Moz Bot crawl the site - but simultaneously continue it blocking its access to Search Engines I have gone through - https://support.google.com/webmasters/answer/93708?hl=en, it says a) Save it in a password-protected directory. Googlebot and other spiders won't be able to access the content- But this way Moz will also not be able to crawl the site b) Use a robots.txt to control access to files and directories on your server - However it also says - It's important to note that even if you use a robots.txt file to block spiders from crawling content on your site, Google could discover it in other ways and add it to our index. c) Use a noindex meta tag to prevent content from appearing in our search results - It also says that a link to the page can still appear in their search results. Because we have to crawl your page in order to see the noindex tag, there's a small chance that Googlebot won't see and respect the noindex meta tag Password Protected thus seems the best way to continue blocking. However, continuing with it will also block Moz bot to crawl the site. Any suggestions Thanks
Moz Bar | | Modi0