Should I "no-index" two exact pages on Google results?
-
Hello everyone,
I recently started a new wordpress website and created a static homepage.
I noticed that on Google search results, there are two different URLs landing on same content page.
I've attached an image to explain what I saw.
Should I "no-index" the page url?
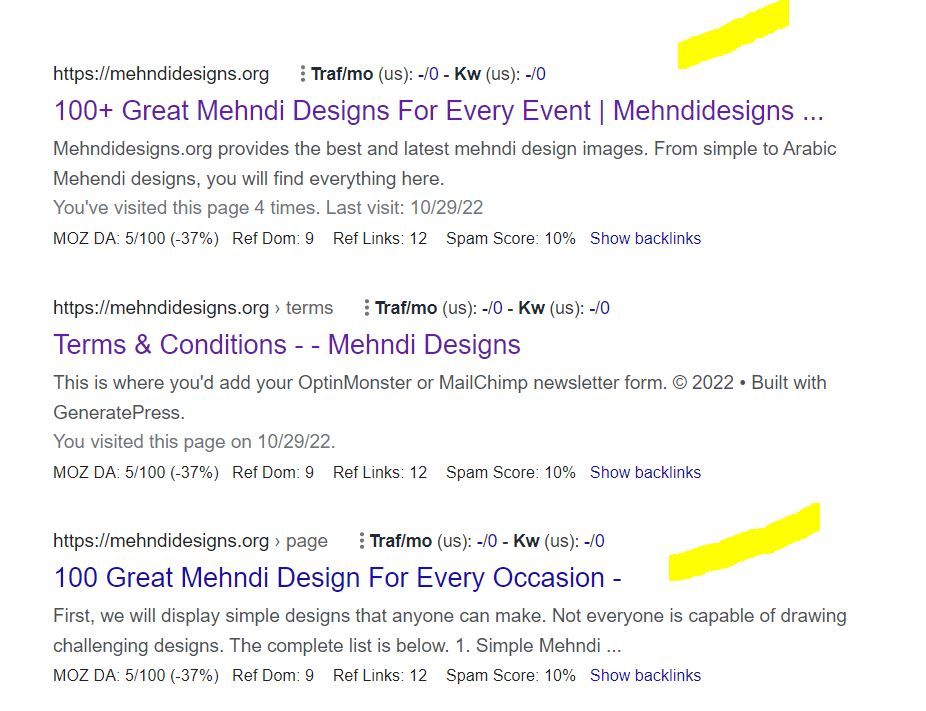
In this picture, the first result is the homepage and I try to rank for that page. The last result is landing on same content with different URL.
So, should I no-index last result as shown in image?
-
In any SEO plugin, you can go to edit the secondary article and in canonical URL you put the link to the home page.
-
@amanda5964 You can use canonical meta tag to tell google that those are the exact same pages. Google will index one of them which google choose best for the SERP.
-
Hi @amanda5964 actually could I ask if there is a reason for having these identical pages? You might want to consider simply combining the pages - i.e. deleting your sub page and redirecting to home if the content is identical.
-
I would not no-index. Typically it is more effective to use a canonical link from the secondary content to the main page you want the traffic directed to.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved Using NoIndex Tag instead of 410 Gone Code on Discontinued products?
Hello everyone, I am very new to SEO and I wanted to get some input & second opinions on a workaround I am planning to implement on our Shopify store. Any suggestions, thoughts, or insight you have are welcome & appreciated! For those who aren't aware, Shopify as a platform doesn't allow us to send a 410 Gone Code/Error under any circumstance. When you delete or archive a product/page, it becomes unavailable on the storefront. Unfortunately, the only thing Shopify natively allows me to do is set up a 301 redirect. So when we are forced to discontinue a product, customers currently get a 404 error when trying to go to that old URL. My planned workaround is to automatically detect when a product has been discontinued and add the NoIndex meta tag to the product page. The product page will stay up but be unavailable for purchase. I am also adjusting the LD+JSON to list the products availability as Discontinued instead of InStock/OutOfStock.
Technical SEO | | BakeryTech
Then I let the page sit for a few months so that crawlers have a chance to recrawl and remove the page from their indexes. I think that is how that works?
Once 3 or 6 months have passed, I plan on archiving the product followed by setting up a 301 redirect pointing to our internal search results page. The redirect will send the to search with a query aimed towards similar products. That should prevent people with open tabs, bookmarks and direct links to that page from receiving a 404 error. I do have Google Search Console setup and integrated with our site, but manually telling google to remove a page obviously only impacts their index. Will this work the way I think it will?
Will search engines remove the page from their indexes if I add the NoIndex meta tag after they have already been index?
Is there a better way I should implement this? P.S. For those wondering why I am not disallowing the page URL to the Robots.txt, Shopify won't allow me to call collection or product data from within the template that assembles the Robots.txt. So I can't automatically add product URLs to the list.0 -

Good to use disallow or noindex for these?
Hello everyone, I am reaching out to seek your expert advice on a few technical SEO aspects related to my website. I highly value your expertise in this field and would greatly appreciate your insights.
Technical SEO | | williamhuynh
Below are the specific areas I would like to discuss: a. Double and Triple filter pages: I have identified certain URLs on my website that have a canonical tag pointing to the main /quick-ship page. These URLs are as follows: https://www.interiorsecrets.com.au/collections/lounge-chairs/quick-ship+black
https://www.interiorsecrets.com.au/collections/lounge-chairs/quick-ship+black+fabric Considering the need to optimize my crawl budget, I would like to seek your advice on whether it would be advisable to disallow or noindex these pages. My understanding is that by disallowing or noindexing these URLs, search engines can avoid wasting resources on crawling and indexing duplicate or filtered content. I would greatly appreciate your guidance on this matter. b. Page URLs with parameters: I have noticed that some of my page URLs include parameters such as ?variant and ?limit. Although these URLs already have canonical tags in place, I would like to understand whether it is still recommended to disallow or noindex them to further conserve crawl budget. My understanding is that by doing so, search engines can prevent the unnecessary expenditure of resources on indexing redundant variations of the same content. I would be grateful for your expert opinion on this matter. Additionally, I would be delighted if you could provide any suggestions regarding internal linking strategies tailored to my website's structure and content. Any insights or recommendations you can offer would be highly valuable to me. Thank you in advance for your time and expertise in addressing these concerns. I genuinely appreciate your assistance. If you require any further information or clarification, please let me know. I look forward to hearing from you. Cheers!0 -

Footer backlink for/to Web Design Agency
I read some old (10+ years) information on whether footer backlinks from the websites that design agencies build are seen as spammy and potentially cause a negative effect. We have over 150 websites that we have built over the last few years, all with sitewide footer backlinks back to our homepage (designed and managed by COMPANY NAME). Semrush flags some of the links as potential spammy links. What are the current thoughts on this type of footer backlink? Are we better to have 1 dofollow backlink and the rest of the website nofollow from each domain?
Link Building | | MultiAdE1 -

Extra Budget Money, What's Best SEO Spend for 7K?
My boss, alerted me that we have 7k in unspent budget for 2022. If you had extra 7k to spend on SEO tool/software/training or whatever, what would you purchase?
Other SEO Tools | | inhouseninja0 -
See Different Landing page for my main keyword in google search result
I have a website like http://www.bannerbuzz.com, i am promoting home page with vinyl banners keyword, but currently i can see my website's review page for vinyl banners result in google, i want to display my home page instead of review page for my keyword result in google, its frequently change, some time i can see home page for it and some time it shows review page as i attached image. i want to show my home page, so can you please help me to solve it, how can i stable my home page with main keywords. OtOXxiE.png
Technical SEO | | CommercePundit0 -

How Does Google's "index" find the location of pages in the "page directory" to return?
This is my understanding of how Google's search works, and I am unsure about one thing in specific: Google continuously crawls websites and stores each page it finds (let's call it "page directory") Google's "page directory" is a cache so it isn't the "live" version of the page Google has separate storage called "the index" which contains all the keywords searched. These keywords in "the index" point to the pages in the "page directory" that contain the same keywords. When someone searches a keyword, that keyword is accessed in the "index" and returns all relevant pages in the "page directory" These returned pages are given ranks based on the algorithm The one part I'm unsure of is how Google's "index" knows the location of relevant pages in the "page directory". The keyword entries in the "index" point to the "page directory" somehow. I'm thinking each page has a url in the "page directory", and the entries in the "index" contain these urls. Since Google's "page directory" is a cache, would the urls be the same as the live website (and would the keywords in the "index" point to these urls)? For example if webpage is found at wwww.website.com/page1, would the "page directory" store this page under that url in Google's cache? The reason I want to discuss this is to know the effects of changing a pages url by understanding how the search process works better.
Technical SEO | | reidsteven750 -
Website Migration - Very Technical Google "Index" Question
This is my understanding of how Google's search works, and I am unsure about one thing in specifc: Google continuously crawls websites and stores each page it finds (let's call it "page directory") Google's "page directory" is a cache so it isn't the "live" version of the page Google has separate storage called "the index" which contains all the keywords searched. These keywords in "the index" point to the pages in the "page directory" that contain the same keywords. When someone searches a keyword, that keyword is accessed in the "index" and returns all relevant pages in the "page directory" These returned pages are given ranks based on the algorithm The one part I'm unsure of is how Google's "index" connects to the "page directory". I'm thinking each page has a url in the "page directory", and the entries in the "index" contain these urls. Since Google's "page directory" is a cache, would the urls be the same as the live website? For example if webpage is found at wwww.website.com/page1, would the "page directory" store this page under that url in Google's cache? The reason I ask is I am starting to work with a client who has a newly developed website. The old website domain and files were located on a GoDaddy account. The new websites files have completely changed location and are now hosted on a separate GoDaddy account, but the domain has remained in the same account. The client has setup domain forwarding/masking to access the files on the separate account. From what I've researched domain masking and SEO don't get along very well. Not only can you not link to specific pages, but if my above assumption is true wouldn't Google have a hard time crawling and storing each page in the cache?
Technical SEO | | reidsteven750 -

How to display the exact url of our subsite in Google
Hi, I'm new to SEO and we just recently relaunched our site. Our site consist of 6 hotels that acts as a subsite. We noticed that when search for one of the hotels what is coming in the google is the main website. Example: We search for flora grand. We expect that in Google it will display the first link as www.florahospitality.com/dubai-flora-grand-hotel.aspx. But it show the main site which is www.florahospitality.com What do I miss here?
Technical SEO | | shebinhassan0